mirror of
https://github.com/bellingcat/tiktok-hashtag-analysis.git
synced 2026-06-11 21:08:31 +03:00
merged changes
This commit is contained in:
12
Pipfile
12
Pipfile
@@ -1,12 +0,0 @@
|
||||
[[source]]
|
||||
url = "https://pypi.python.org/simple"
|
||||
verify_ssl = true
|
||||
name = "pypi"
|
||||
|
||||
[packages]
|
||||
|
||||
[dev-packages]
|
||||
pylint = "*"
|
||||
|
||||
[requires]
|
||||
python_version = "3.6+"
|
||||
170
Pipfile.lock
generated
170
Pipfile.lock
generated
@@ -1,170 +0,0 @@
|
||||
{
|
||||
"_meta": {
|
||||
"hash": {
|
||||
"sha256": "54bb714adcfa14c627d84696f321a9d68f7400cdef871098e6f49c81d854b478"
|
||||
},
|
||||
"pipfile-spec": 6,
|
||||
"requires": {
|
||||
"python_version": "3.6+"
|
||||
},
|
||||
"sources": [
|
||||
{
|
||||
"name": "pypi",
|
||||
"url": "https://pypi.python.org/simple",
|
||||
"verify_ssl": true
|
||||
}
|
||||
]
|
||||
},
|
||||
"default": {},
|
||||
"develop": {
|
||||
"astroid": {
|
||||
"hashes": [
|
||||
"sha256:1efdf4e867d4d8ba4a9f6cf9ce07cd182c4c41de77f23814feb27ca93ca9d877",
|
||||
"sha256:506daabe5edffb7e696ad82483ad0228245a9742ed7d2d8c9cdb31537decf9f6"
|
||||
],
|
||||
"version": "==2.9.3"
|
||||
},
|
||||
"isort": {
|
||||
"hashes": [
|
||||
"sha256:6f62d78e2f89b4500b080fe3a81690850cd254227f27f75c3a0c491a1f351ba7",
|
||||
"sha256:e8443a5e7a020e9d7f97f1d7d9cd17c88bcb3bc7e218bf9cf5095fe550be2951"
|
||||
],
|
||||
"version": "==5.10.1"
|
||||
},
|
||||
"lazy-object-proxy": {
|
||||
"hashes": [
|
||||
"sha256:043651b6cb706eee4f91854da4a089816a6606c1428fd391573ef8cb642ae4f7",
|
||||
"sha256:07fa44286cda977bd4803b656ffc1c9b7e3bc7dff7d34263446aec8f8c96f88a",
|
||||
"sha256:12f3bb77efe1367b2515f8cb4790a11cffae889148ad33adad07b9b55e0ab22c",
|
||||
"sha256:2052837718516a94940867e16b1bb10edb069ab475c3ad84fd1e1a6dd2c0fcfc",
|
||||
"sha256:2130db8ed69a48a3440103d4a520b89d8a9405f1b06e2cc81640509e8bf6548f",
|
||||
"sha256:39b0e26725c5023757fc1ab2a89ef9d7ab23b84f9251e28f9cc114d5b59c1b09",
|
||||
"sha256:46ff647e76f106bb444b4533bb4153c7370cdf52efc62ccfc1a28bdb3cc95442",
|
||||
"sha256:4dca6244e4121c74cc20542c2ca39e5c4a5027c81d112bfb893cf0790f96f57e",
|
||||
"sha256:553b0f0d8dbf21890dd66edd771f9b1b5f51bd912fa5f26de4449bfc5af5e029",
|
||||
"sha256:677ea950bef409b47e51e733283544ac3d660b709cfce7b187f5ace137960d61",
|
||||
"sha256:6a24357267aa976abab660b1d47a34aaf07259a0c3859a34e536f1ee6e76b5bb",
|
||||
"sha256:6a6e94c7b02641d1311228a102607ecd576f70734dc3d5e22610111aeacba8a0",
|
||||
"sha256:6aff3fe5de0831867092e017cf67e2750c6a1c7d88d84d2481bd84a2e019ec35",
|
||||
"sha256:6ecbb350991d6434e1388bee761ece3260e5228952b1f0c46ffc800eb313ff42",
|
||||
"sha256:7096a5e0c1115ec82641afbdd70451a144558ea5cf564a896294e346eb611be1",
|
||||
"sha256:70ed0c2b380eb6248abdef3cd425fc52f0abd92d2b07ce26359fcbc399f636ad",
|
||||
"sha256:8561da8b3dd22d696244d6d0d5330618c993a215070f473b699e00cf1f3f6443",
|
||||
"sha256:85b232e791f2229a4f55840ed54706110c80c0a210d076eee093f2b2e33e1bfd",
|
||||
"sha256:898322f8d078f2654d275124a8dd19b079080ae977033b713f677afcfc88e2b9",
|
||||
"sha256:8f3953eb575b45480db6568306893f0bd9d8dfeeebd46812aa09ca9579595148",
|
||||
"sha256:91ba172fc5b03978764d1df5144b4ba4ab13290d7bab7a50f12d8117f8630c38",
|
||||
"sha256:9d166602b525bf54ac994cf833c385bfcc341b364e3ee71e3bf5a1336e677b55",
|
||||
"sha256:a57d51ed2997e97f3b8e3500c984db50a554bb5db56c50b5dab1b41339b37e36",
|
||||
"sha256:b9e89b87c707dd769c4ea91f7a31538888aad05c116a59820f28d59b3ebfe25a",
|
||||
"sha256:bb8c5fd1684d60a9902c60ebe276da1f2281a318ca16c1d0a96db28f62e9166b",
|
||||
"sha256:c19814163728941bb871240d45c4c30d33b8a2e85972c44d4e63dd7107faba44",
|
||||
"sha256:c4ce15276a1a14549d7e81c243b887293904ad2d94ad767f42df91e75fd7b5b6",
|
||||
"sha256:c7a683c37a8a24f6428c28c561c80d5f4fd316ddcf0c7cab999b15ab3f5c5c69",
|
||||
"sha256:d609c75b986def706743cdebe5e47553f4a5a1da9c5ff66d76013ef396b5a8a4",
|
||||
"sha256:d66906d5785da8e0be7360912e99c9188b70f52c422f9fc18223347235691a84",
|
||||
"sha256:dd7ed7429dbb6c494aa9bc4e09d94b778a3579be699f9d67da7e6804c422d3de",
|
||||
"sha256:df2631f9d67259dc9620d831384ed7732a198eb434eadf69aea95ad18c587a28",
|
||||
"sha256:e368b7f7eac182a59ff1f81d5f3802161932a41dc1b1cc45c1f757dc876b5d2c",
|
||||
"sha256:e40f2013d96d30217a51eeb1db28c9ac41e9d0ee915ef9d00da639c5b63f01a1",
|
||||
"sha256:f769457a639403073968d118bc70110e7dce294688009f5c24ab78800ae56dc8",
|
||||
"sha256:fccdf7c2c5821a8cbd0a9440a456f5050492f2270bd54e94360cac663398739b",
|
||||
"sha256:fd45683c3caddf83abbb1249b653a266e7069a09f486daa8863fb0e7496a9fdb"
|
||||
],
|
||||
"version": "==1.7.1"
|
||||
},
|
||||
"mccabe": {
|
||||
"hashes": [
|
||||
"sha256:ab8a6258860da4b6677da4bd2fe5dc2c659cff31b3ee4f7f5d64e79735b80d42",
|
||||
"sha256:dd8d182285a0fe56bace7f45b5e7d1a6ebcbf524e8f3bd87eb0f125271b8831f"
|
||||
],
|
||||
"version": "==0.6.1"
|
||||
},
|
||||
"platformdirs": {
|
||||
"hashes": [
|
||||
"sha256:7535e70dfa32e84d4b34996ea99c5e432fa29a708d0f4e394bbcb2a8faa4f16d",
|
||||
"sha256:bcae7cab893c2d310a711b70b24efb93334febe65f8de776ee320b517471e227"
|
||||
],
|
||||
"version": "==2.5.1"
|
||||
},
|
||||
"pylint": {
|
||||
"hashes": [
|
||||
"sha256:9d945a73640e1fec07ee34b42f5669b770c759acd536ec7b16d7e4b87a9c9ff9",
|
||||
"sha256:daabda3f7ed9d1c60f52d563b1b854632fd90035bcf01443e234d3dc794e3b74"
|
||||
],
|
||||
"index": "pypi",
|
||||
"version": "==2.12.2"
|
||||
},
|
||||
"toml": {
|
||||
"hashes": [
|
||||
"sha256:806143ae5bfb6a3c6e736a764057db0e6a0e05e338b5630894a5f779cabb4f9b",
|
||||
"sha256:b3bda1d108d5dd99f4a20d24d9c348e91c4db7ab1b749200bded2f839ccbe68f"
|
||||
],
|
||||
"version": "==0.10.2"
|
||||
},
|
||||
"typing-extensions": {
|
||||
"hashes": [
|
||||
"sha256:1a9462dcc3347a79b1f1c0271fbe79e844580bb598bafa1ed208b94da3cdcd42",
|
||||
"sha256:21c85e0fe4b9a155d0799430b0ad741cdce7e359660ccbd8b530613e8df88ce2"
|
||||
],
|
||||
"markers": "python_version < '3.10'",
|
||||
"version": "==4.1.1"
|
||||
},
|
||||
"wrapt": {
|
||||
"hashes": [
|
||||
"sha256:086218a72ec7d986a3eddb7707c8c4526d677c7b35e355875a0fe2918b059179",
|
||||
"sha256:0877fe981fd76b183711d767500e6b3111378ed2043c145e21816ee589d91096",
|
||||
"sha256:0a017a667d1f7411816e4bf214646d0ad5b1da2c1ea13dec6c162736ff25a374",
|
||||
"sha256:0cb23d36ed03bf46b894cfec777eec754146d68429c30431c99ef28482b5c1df",
|
||||
"sha256:1fea9cd438686e6682271d36f3481a9f3636195578bab9ca3382e2f5f01fc185",
|
||||
"sha256:220a869982ea9023e163ba915077816ca439489de6d2c09089b219f4e11b6785",
|
||||
"sha256:25b1b1d5df495d82be1c9d2fad408f7ce5ca8a38085e2da41bb63c914baadff7",
|
||||
"sha256:2dded5496e8f1592ec27079b28b6ad2a1ef0b9296d270f77b8e4a3a796cf6909",
|
||||
"sha256:2ebdde19cd3c8cdf8df3fc165bc7827334bc4e353465048b36f7deeae8ee0918",
|
||||
"sha256:43e69ffe47e3609a6aec0fe723001c60c65305784d964f5007d5b4fb1bc6bf33",
|
||||
"sha256:46f7f3af321a573fc0c3586612db4decb7eb37172af1bc6173d81f5b66c2e068",
|
||||
"sha256:47f0a183743e7f71f29e4e21574ad3fa95676136f45b91afcf83f6a050914829",
|
||||
"sha256:498e6217523111d07cd67e87a791f5e9ee769f9241fcf8a379696e25806965af",
|
||||
"sha256:4b9c458732450ec42578b5642ac53e312092acf8c0bfce140ada5ca1ac556f79",
|
||||
"sha256:51799ca950cfee9396a87f4a1240622ac38973b6df5ef7a41e7f0b98797099ce",
|
||||
"sha256:5601f44a0f38fed36cc07db004f0eedeaadbdcec90e4e90509480e7e6060a5bc",
|
||||
"sha256:5f223101f21cfd41deec8ce3889dc59f88a59b409db028c469c9b20cfeefbe36",
|
||||
"sha256:610f5f83dd1e0ad40254c306f4764fcdc846641f120c3cf424ff57a19d5f7ade",
|
||||
"sha256:6a03d9917aee887690aa3f1747ce634e610f6db6f6b332b35c2dd89412912bca",
|
||||
"sha256:705e2af1f7be4707e49ced9153f8d72131090e52be9278b5dbb1498c749a1e32",
|
||||
"sha256:766b32c762e07e26f50d8a3468e3b4228b3736c805018e4b0ec8cc01ecd88125",
|
||||
"sha256:77416e6b17926d953b5c666a3cb718d5945df63ecf922af0ee576206d7033b5e",
|
||||
"sha256:778fd096ee96890c10ce96187c76b3e99b2da44e08c9e24d5652f356873f6709",
|
||||
"sha256:78dea98c81915bbf510eb6a3c9c24915e4660302937b9ae05a0947164248020f",
|
||||
"sha256:7dd215e4e8514004c8d810a73e342c536547038fb130205ec4bba9f5de35d45b",
|
||||
"sha256:7dde79d007cd6dfa65afe404766057c2409316135cb892be4b1c768e3f3a11cb",
|
||||
"sha256:81bd7c90d28a4b2e1df135bfbd7c23aee3050078ca6441bead44c42483f9ebfb",
|
||||
"sha256:85148f4225287b6a0665eef08a178c15097366d46b210574a658c1ff5b377489",
|
||||
"sha256:865c0b50003616f05858b22174c40ffc27a38e67359fa1495605f96125f76640",
|
||||
"sha256:87883690cae293541e08ba2da22cacaae0a092e0ed56bbba8d018cc486fbafbb",
|
||||
"sha256:8aab36778fa9bba1a8f06a4919556f9f8c7b33102bd71b3ab307bb3fecb21851",
|
||||
"sha256:8c73c1a2ec7c98d7eaded149f6d225a692caa1bd7b2401a14125446e9e90410d",
|
||||
"sha256:936503cb0a6ed28dbfa87e8fcd0a56458822144e9d11a49ccee6d9a8adb2ac44",
|
||||
"sha256:944b180f61f5e36c0634d3202ba8509b986b5fbaf57db3e94df11abee244ba13",
|
||||
"sha256:96b81ae75591a795d8c90edc0bfaab44d3d41ffc1aae4d994c5aa21d9b8e19a2",
|
||||
"sha256:981da26722bebb9247a0601e2922cedf8bb7a600e89c852d063313102de6f2cb",
|
||||
"sha256:ae9de71eb60940e58207f8e71fe113c639da42adb02fb2bcbcaccc1ccecd092b",
|
||||
"sha256:b73d4b78807bd299b38e4598b8e7bd34ed55d480160d2e7fdaabd9931afa65f9",
|
||||
"sha256:d4a5f6146cfa5c7ba0134249665acd322a70d1ea61732723c7d3e8cc0fa80755",
|
||||
"sha256:dd91006848eb55af2159375134d724032a2d1d13bcc6f81cd8d3ed9f2b8e846c",
|
||||
"sha256:e05e60ff3b2b0342153be4d1b597bbcfd8330890056b9619f4ad6b8d5c96a81a",
|
||||
"sha256:e6906d6f48437dfd80464f7d7af1740eadc572b9f7a4301e7dd3d65db285cacf",
|
||||
"sha256:e92d0d4fa68ea0c02d39f1e2f9cb5bc4b4a71e8c442207433d8db47ee79d7aa3",
|
||||
"sha256:e94b7d9deaa4cc7bac9198a58a7240aaf87fe56c6277ee25fa5b3aa1edebd229",
|
||||
"sha256:ea3e746e29d4000cd98d572f3ee2a6050a4f784bb536f4ac1f035987fc1ed83e",
|
||||
"sha256:ec7e20258ecc5174029a0f391e1b948bf2906cd64c198a9b8b281b811cbc04de",
|
||||
"sha256:ec9465dd69d5657b5d2fa6133b3e1e989ae27d29471a672416fd729b429eb554",
|
||||
"sha256:f122ccd12fdc69628786d0c947bdd9cb2733be8f800d88b5a37c57f1f1d73c10",
|
||||
"sha256:f99c0489258086308aad4ae57da9e8ecf9e1f3f30fa35d5e170b4d4896554d80",
|
||||
"sha256:f9c51d9af9abb899bd34ace878fbec8bf357b3194a10c4e8e0a25512826ef056",
|
||||
"sha256:fd76c47f20984b43d93de9a82011bb6e5f8325df6c9ed4d8310029a55fa361ea"
|
||||
],
|
||||
"version": "==1.13.3"
|
||||
}
|
||||
}
|
||||
}
|
||||
140
README.md
140
README.md
@@ -2,62 +2,64 @@
|
||||
The tool helps to download posts and videos from TikTok for a given set of hashtags. It uses the [tiktok-scraper](https://github.com/drawrowfly/tiktok-scraper) Node package to download the posts and videos.
|
||||
|
||||
## Pre-requisites
|
||||
1. Make sure you have Python 3.6 or a later version installed
|
||||
2. Install the [Pipenv](https://pipenv.pypa.io/en/latest/) Python package using the command:
|
||||
1. Make sure you have Python 3.6 or a later version installed.
|
||||
2. Download and install TikTok scraper: https://github.com/drawrowfly/tiktok-scraper
|
||||
3. (Optional) create and activate a virtual environment for this tool, for example by executing the following command, which creates the `env` virtual environment:
|
||||
|
||||
`pip3 install pipenv`
|
||||
`python3 -m venv env`
|
||||
|
||||
3. Install the dependencies of this tool using the command:
|
||||
|
||||
`pipenv install`
|
||||
4. Install the Python package dependencies for this tool by executing the command:
|
||||
|
||||
3. Download and install [TikTok scraper](https://github.com/drawrowfly/tiktok-scraper)
|
||||
`pip install -r requirements.txt`
|
||||
|
||||
### Options for running run_downloader.py
|
||||
## About the tool
|
||||
### Command-line arguments
|
||||
```
|
||||
$ python run_downloader.py -h
|
||||
usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
|
||||
|
||||
$ python run_downloader.py -h
|
||||
usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
|
||||
Download the tiktoks for the requested hashtags
|
||||
|
||||
Download the tiktoks for the requested hashtags
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-t [T [T ...]] List of hashtags
|
||||
-f F File name with the list of hashtags
|
||||
-p Download posts
|
||||
-v Download videos
|
||||
```
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-t [T [T ...]] List of hashtags
|
||||
-f F File name with the list of hashtags
|
||||
-p Download posts
|
||||
-v Download videos
|
||||
### Structure of output data
|
||||
```
|
||||
$ tree ../data
|
||||
../data
|
||||
├── ids
|
||||
│ └── post_ids.json
|
||||
├── log
|
||||
│ └── log.json
|
||||
├── london
|
||||
│ └── posts
|
||||
│ └── data.json
|
||||
├── newyork
|
||||
│ └── posts
|
||||
│ └── data.json
|
||||
└── paris
|
||||
└── posts
|
||||
└── data.json
|
||||
```
|
||||
|
||||
### Data organization
|
||||
|
||||
$ tree ../data
|
||||
../data
|
||||
├── ids
|
||||
│ └── post_ids.json
|
||||
├── log
|
||||
│ └── log.json
|
||||
├── london
|
||||
│ └── posts
|
||||
│ └── data.json
|
||||
├── newyork
|
||||
│ └── posts
|
||||
│ └── data.json
|
||||
└── paris
|
||||
└── posts
|
||||
└── data.json
|
||||
|
||||
The `data` folder contains all the downloaded data as shown in the picture above.
|
||||
1. the `log` folder contains log.json which records the total number of downloaded posts and videos for the hashtags against the time stamp of when the script is run.
|
||||
2. the `ids` folder contains two files `post_ids.json` and `video_ids.json` that records the ids of the downloaded posts and videos for each hashtag.
|
||||
3. Each hashtag has a folder with two subfolders `posts` and `videos` that store posts and videos respectively. The posts are stored in the `data.json` file in the `posts` folder, and videos are stored as the `.mp4` files in the `videos` folder.
|
||||
The `data` folder contains all the downloaded data as shown in the tree diagram above.
|
||||
- The `log` folder contains the `log.json` file, which records the total number of downloaded posts and videos for the hashtags against the timestamp of when the script was run.
|
||||
- The `ids` folder contains two files `post_ids.json` and `video_ids.json` that record the ids of the downloaded posts and videos for each hashtag.
|
||||
- Each hashtag has a folder with two subfolders `posts` and `videos` that store posts and videos respectively. The posts are stored in the `data.json` file in the `posts` folder, and videos are stored as the `.mp4` files in the `videos` folder.
|
||||
|
||||
|
||||
|
||||
### Post download
|
||||
Run the run_downloader.py with the following option:
|
||||
## How to use
|
||||
### Post downloading
|
||||
Running the `run_downloader.py` script with the following options will scrape posts containing the hashtags `#london`, `#paris`, or `#newyork`:
|
||||
|
||||
python3 run_downloader.py -t london paris newyork -p
|
||||
|
||||
which will produce an output similar to the following log:
|
||||
and will produce an output similar to the following log:
|
||||
|
||||
$ python3 run_downloader.py -t london paris newyork -p
|
||||
['london', 'paris', 'newyork']
|
||||
@@ -75,29 +77,53 @@ which will produce an output similar to the following log:
|
||||
Total posts for the hashtag newyork are: 941
|
||||
Successfully logged 2864 entries!!!!
|
||||
|
||||
1. The `-t` option allows to type in a space-separated list of hashtags as a command line argument.
|
||||
2. The `-p` option specifies the download posts option.
|
||||
- The `-t` flag allows a space-separated list of hashtags to be specified as a command line argument
|
||||
- The `-p` flag specifies that posts, not videos, will be downloaded
|
||||
|
||||
|
||||
### Video download
|
||||
### Video downloading
|
||||
Running the `run_downloader.py` script with the following options will scrape trending videos containing the hashtags `#london`, `#paris`, or `#newyork`:
|
||||
` python3 run_downloader.py -t london -v`
|
||||
|
||||
1. The `-t` option allows to type in a space-separated list of hashtags as a command line argument.
|
||||
2. The `-v` option is for downloading the videos
|
||||
The above code download all the trending videos for the hashtag london. Note that video downloading is a time and data rate consuming task, as a result we strongly recommend using one hashtag at a time to avoid complications.
|
||||
- The `-t` flag allows a space-separated list of hashtags to be specified as a command line argument
|
||||
- The `-v` flag specifies that videos, not posts, will be downloaded
|
||||
|
||||
Note that video downloading is a time and data rate consuming task, as a result we strongly recommend using one hashtag at a time when using the `-v` flag to avoid complications.
|
||||
|
||||
## Analyzing results
|
||||
### Top n hashtag occurrences
|
||||
In the analytics folder, the file `hashtag_frequencies.py` will plot the frequencies of top occurring hashtags in a given set of posts.
|
||||
Assume we want to plot the graph of top 20 occurring hashtags in the downloaded posts of the hashtag london.
|
||||
The script `hashtag_frequencies.py` analyzes the frequencies of top occurring hashtags in a given set of posts.
|
||||
|
||||
1. Plotting the saving the image as a png file: ` python3 hashtag_frequencies.py -p ../data/london/posts/data.json 20`
|
||||
```
|
||||
python hashtag_frequencies.py --help
|
||||
usage: hashtag_frequencies.py [-h] [-p] [-d] input_file n
|
||||
|
||||
<img width="1390" alt="Screenshot 2022-02-25 at 19 45 40" src="https://user-images.githubusercontent.com/72805812/155770710-0d167bbb-4c44-44d2-ba1c-fa57026afea8.png">
|
||||
positional arguments:
|
||||
input_file The json hashtag file name
|
||||
n The number of top n occurrences
|
||||
|
||||
The figure above shows the top 20 occurring hashtags among all the posts downloaded for the hashtag london. Clearly, the highest occurrence will be of the hashtag london as the file `data/london/posts/data.json` contain all the posts with hashtag london.
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-p, --plot Plot the occurrences
|
||||
-d, --print List top n hashtags
|
||||
```
|
||||
|
||||
2. Printing the result in the shell: ` python3 hashtag_frequencies.py -d ../data/london/posts/data.json 20`
|
||||
Assume we want to analyze the top 20 occurring hashtags in the downloaded posts of the `#london` hashtag.
|
||||
|
||||
- The results can be plotted and saved as a PNG file by executing the following command:
|
||||
|
||||
`python3 hashtag_frequencies.py -p ../data/london/posts/data.json 20`
|
||||
|
||||
which will produce a figure similar to that shown below:
|
||||
|
||||
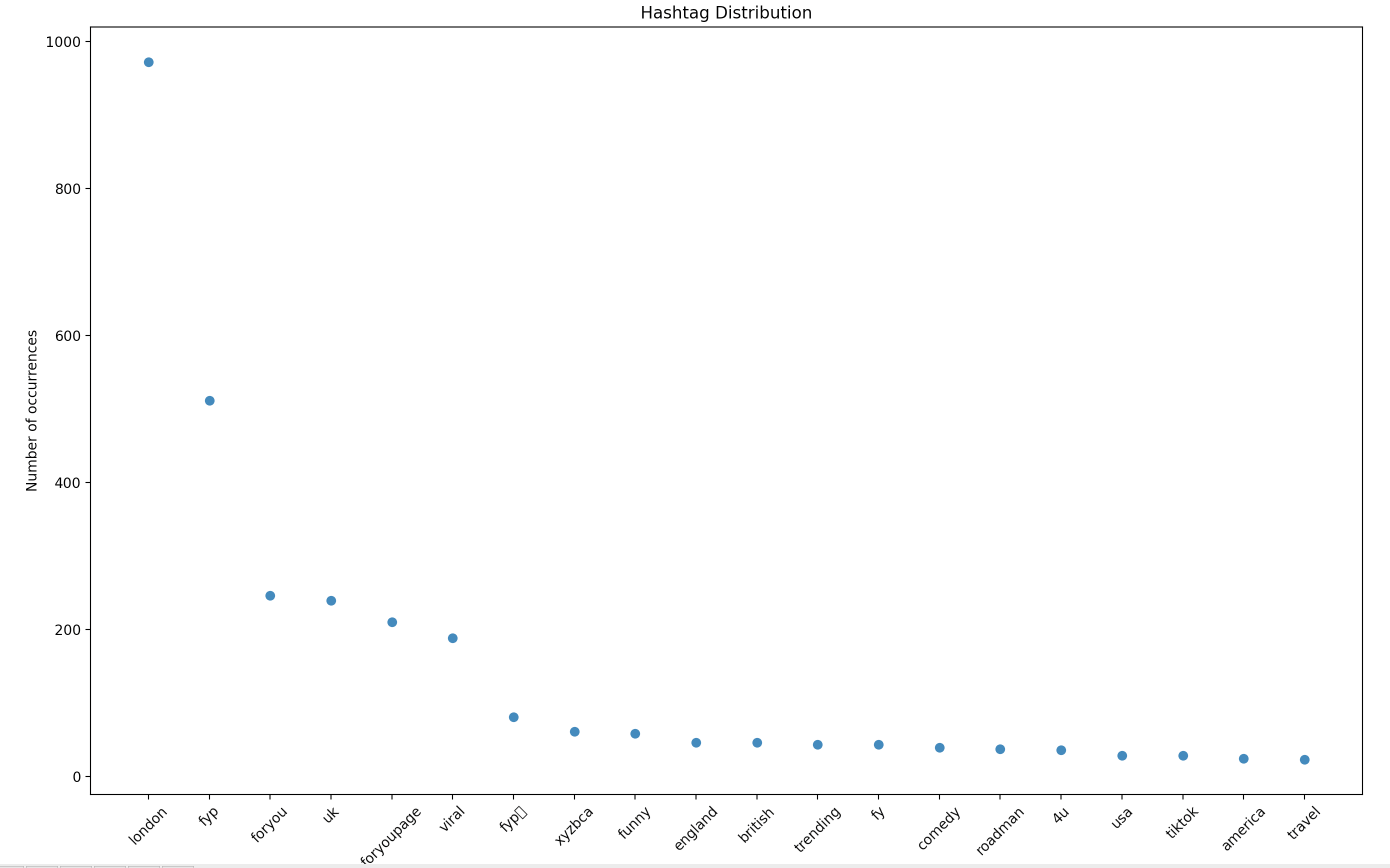
|
||||
|
||||
Clearly, the highest occurrence will be of the `#london` hashtag, as all posts in the file `data/london/posts/data.json` contain the hashtag `#london`.
|
||||
|
||||
- The results can be displayed in tabular form by executing the following command:
|
||||
|
||||
`python3 hashtag_frequencies.py -d ../data/london/posts/data.json 20`
|
||||
|
||||
which will produce a terminal output similar to the following:
|
||||
```
|
||||
Rank Hashtag Occurrences Frequency (Occurrences/Total-Posts(total_posts))
|
||||
0 london 962 1.0
|
||||
@@ -122,4 +148,4 @@ The figure above shows the top 20 occurring hashtags among all the posts downloa
|
||||
19 america 20 0.02079002079002079
|
||||
```
|
||||
|
||||
The same result of 1 is printed in the shell. The last column shows the ratio of the occurrence to the total posts.
|
||||
The `Frequency` column shows the ratio of the occurrence to the total number of downloaded posts.
|
||||
@@ -1,4 +0,0 @@
|
||||
"""
|
||||
Yet to be written ...
|
||||
"""
|
||||
|
||||
32
logging.ini
Normal file
32
logging.ini
Normal file
@@ -0,0 +1,32 @@
|
||||
[loggers]
|
||||
keys=root
|
||||
|
||||
[handlers]
|
||||
keys=consoleHandler,fileHandler
|
||||
|
||||
[formatters]
|
||||
keys=consoleFormatter,fileFormatter
|
||||
|
||||
[logger_root]
|
||||
level=INFO
|
||||
handlers=consoleHandler,fileHandler
|
||||
|
||||
[handler_consoleHandler]
|
||||
class=StreamHandler
|
||||
level=DEBUG
|
||||
formatter=consoleFormatter
|
||||
args=(sys.stdout,)
|
||||
|
||||
[handler_fileHandler]
|
||||
class=FileHandler
|
||||
level=WARNING
|
||||
formatter=fileFormatter
|
||||
args=("../logfile.log",)
|
||||
|
||||
[formatter_fileFormatter]
|
||||
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
||||
datefmt=
|
||||
|
||||
[formatter_consoleFormatter]
|
||||
format=%(levelname)s - %(message)s
|
||||
datefmt=
|
||||
1
requirements.txt
Normal file
1
requirements.txt
Normal file
@@ -0,0 +1 @@
|
||||
matplotlib==3.5.2
|
||||
@@ -1,12 +1,22 @@
|
||||
from collections import namedtuple
|
||||
import file_methods
|
||||
|
||||
# setting up the logging
|
||||
import logging
|
||||
from logging.config import fileConfig
|
||||
|
||||
fileConfig('../logging.ini')
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
|
||||
|
||||
"""
|
||||
The file contains several functions that perform data processing related tasks.
|
||||
"""
|
||||
|
||||
|
||||
difference = namedtuple("difference", "new_ids size")
|
||||
diff = namedtuple("difference", "ids filter_posts")
|
||||
total = namedtuple("total", "total unique")
|
||||
|
||||
|
||||
@@ -15,23 +25,29 @@ def get_difference(tag, file, ids):
|
||||
Compares two sets of ids and returns the difference of the two sets.
|
||||
Purpose - user to filter out the new ids by comparing the set of id list (ids/post_ids.json or videos_ids.json) and the list of newly downloaded ids.
|
||||
"""
|
||||
maiden_entry = False
|
||||
filter_posts = False
|
||||
current_id_data = file_methods.get_data(file)
|
||||
if tag in current_id_data:
|
||||
current_ids = current_id_data[tag]
|
||||
set1 = set(current_ids)
|
||||
set2 = set(ids)
|
||||
new_ids = set2.difference(set1)
|
||||
if new_ids:
|
||||
new_ids = list(new_ids)
|
||||
size = len(new_ids)
|
||||
diff = difference(new_ids, size)
|
||||
return (diff, maiden_entry)
|
||||
set_current_ids = set(current_ids)
|
||||
total_current_ids = len(set_current_ids)
|
||||
set_ids = set(ids)
|
||||
new_ids = set_ids.difference(set_current_ids)
|
||||
if not new_ids:
|
||||
return None
|
||||
else:
|
||||
return ([], maiden_entry)
|
||||
else:
|
||||
maiden_entry = True
|
||||
return (ids, maiden_entry)
|
||||
new_ids = list(new_ids)
|
||||
total_new_ids = len(new_ids)
|
||||
if total_new_ids == total_current_ids:
|
||||
filter_posts = False
|
||||
new_data = diff(new_ids, filter_posts)
|
||||
else:
|
||||
new_data = diff(new_ids, filter_posts)
|
||||
return new_data
|
||||
else:
|
||||
filter_posts = True
|
||||
new_data = diff(ids, filter_posts)
|
||||
return new_data
|
||||
|
||||
|
||||
def extract_posts(settings, file_name, tag):
|
||||
@@ -40,13 +56,13 @@ def extract_posts(settings, file_name, tag):
|
||||
"""
|
||||
ids = []
|
||||
posts = []
|
||||
new_posts = []
|
||||
|
||||
posts = file_methods.get_data(file_name)
|
||||
for post in posts:
|
||||
ids.append(post["id"])
|
||||
|
||||
if not ids:
|
||||
print(f"WARNING: no posts were found for {tag} in the file - {file_name}")
|
||||
logger.warn(f"WARNING: no posts were found for {tag} in the file - {file_name}")
|
||||
return
|
||||
|
||||
status = file_methods.check_existence(settings["post_ids"], "file")
|
||||
@@ -54,18 +70,17 @@ def extract_posts(settings, file_name, tag):
|
||||
new_data = (ids, posts)
|
||||
return new_data
|
||||
else:
|
||||
res = get_difference(tag, settings["post_ids"], ids)
|
||||
if res[1]:
|
||||
new_data = (ids, posts)
|
||||
new_ids = get_difference(tag, settings["post_ids"], ids)
|
||||
if not new_ids:
|
||||
logger.warn(f"WARNING: No new posts were found in the downloaded file - {file_name}")
|
||||
return
|
||||
elif new_ids.filter_posts:
|
||||
new_posts = [post for post in posts if post['id'] in new_ids.ids]
|
||||
new_data = (new_ids.ids, new_posts)
|
||||
return new_data
|
||||
else:
|
||||
if res[0]:
|
||||
new_posts = [ post for post in posts if post['id'] in res[0].new_ids ]
|
||||
new_data = (res[0].new_ids, new_posts)
|
||||
return new_data
|
||||
else:
|
||||
print(f"WARNING: No new posts were found in the downloaded file - {file_name}")
|
||||
return
|
||||
new_data = (new_ids.ids, new_posts)
|
||||
return new_data
|
||||
|
||||
|
||||
def extract_videos(settings, tag, download_list):
|
||||
@@ -77,16 +92,12 @@ def extract_videos(settings, tag, download_list):
|
||||
new_data = download_list
|
||||
return new_data
|
||||
else:
|
||||
res = get_difference(tag, settings["video_ids"], download_list)
|
||||
if res[1]:
|
||||
return download_list
|
||||
new_videos = get_difference(tag, settings["video_ids"], download_list)
|
||||
if not new_videos:
|
||||
logger.warn(f"WARNING: No new videos were found for the {tag} in the downloaded folder.")
|
||||
return
|
||||
else:
|
||||
if res[0]:
|
||||
new_data = res[0].new_ids
|
||||
return new_data
|
||||
else:
|
||||
print(f"WARNING: No new videos were found for the {tag} in the downloaded folder.")
|
||||
return
|
||||
return new_videos.ids
|
||||
|
||||
|
||||
def update_posts(file_path, file_type, new_data, tag=None):
|
||||
@@ -136,8 +147,8 @@ def print_total(file_path, tag, data_type):
|
||||
"""
|
||||
total = get_total_posts(file_path, tag)
|
||||
if (total.total == total.unique):
|
||||
print(f"Total {data_type} for the hashtag {tag} are: {total.total}")
|
||||
logger.info(f"Total {data_type} for the hashtag {tag} are: {total.total}")
|
||||
return
|
||||
else:
|
||||
print(f"WARNING: out of total {data_type} for the hashtag {tag} {total.total}, only {total.unique} are unique. Something is going wrong...")
|
||||
logger.warn(f"WARNING: out of total {data_type} for the hashtag {tag} {total.total}, only {total.unique} are unique. Something is going wrong...")
|
||||
return
|
||||
|
||||
@@ -4,6 +4,15 @@ import global_data
|
||||
import shutil
|
||||
|
||||
|
||||
# setting up the logging
|
||||
import logging
|
||||
from logging.config import fileConfig
|
||||
|
||||
fileConfig('../logging.ini')
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
|
||||
"""
|
||||
The file contains the functions that operate on files, such as writing or reading from files etc.
|
||||
"""
|
||||
@@ -18,7 +27,7 @@ def create_file(name, file_type):
|
||||
elif (file_type == "file"):
|
||||
with open(name, "w"): pass
|
||||
else:
|
||||
raise OSError(f"{file_type} has to be a 'dir' or a 'file'!!!")
|
||||
logger.exception(f"{file_type} has to be a 'dir' or a 'file'!!!")
|
||||
return
|
||||
|
||||
|
||||
@@ -31,7 +40,7 @@ def check_existence(file_path, file_type):
|
||||
elif (file_type == "dir"):
|
||||
return os.path.isdir(file_path)
|
||||
else:
|
||||
raise OSError(f"{file_type} has to be a 'dir' or a 'file'!!!")
|
||||
logger.exception(f"{file_type} has to be a 'dir' or a 'file'!!!")
|
||||
|
||||
|
||||
def check_file(file_path, file_type):
|
||||
@@ -62,7 +71,7 @@ def download_posts(settings, tag):
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return new_file
|
||||
else:
|
||||
print(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
|
||||
logger.warn(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return
|
||||
except: raise
|
||||
@@ -136,20 +145,15 @@ def log_writer(log_data):
|
||||
log_dict[ele[0]] = { ele[1][0] : ele[1][1] }
|
||||
total += ele[1][1]
|
||||
|
||||
logger = global_data.FILES["logger"]
|
||||
now = datetime.now()
|
||||
now_str = now.strftime("%d-%m-%Y %H:%M:%S")
|
||||
status = check_existence(logger, "file")
|
||||
if status:
|
||||
data = get_data(logger)
|
||||
data[now_str] = log_dict
|
||||
dump_data(logger, data)
|
||||
else:
|
||||
data = { now_str : log_dict }
|
||||
dump_data(logger, data)
|
||||
print(f"Successfully logged {total} entries!!!!")
|
||||
data = { now_str : log_dict }
|
||||
|
||||
logger.warn(data)
|
||||
logger.info(f"Successfully logged {total} entries!!!!")
|
||||
return
|
||||
except: raise
|
||||
except:
|
||||
logger.exception()
|
||||
|
||||
|
||||
def id_writer(file_path, new_data, tag, status):
|
||||
@@ -172,10 +176,11 @@ def id_writer(file_path, new_data, tag, status):
|
||||
else:
|
||||
data = { tag : new_data }
|
||||
dump_data(file_path, data)
|
||||
print(f"SUCCESS - {total} entries added to {file_path}!!!")
|
||||
logger.info(f"SUCCESS - {total} entries added to {file_path}!!!")
|
||||
log_data = (tag, total)
|
||||
return log_data
|
||||
except: raise
|
||||
except:
|
||||
logger.exception()
|
||||
|
||||
|
||||
def post_writer(file_path, new_data, status):
|
||||
@@ -195,9 +200,10 @@ def post_writer(file_path, new_data, status):
|
||||
else:
|
||||
data = new_data
|
||||
dump_data(file_path, data)
|
||||
print(f"SUCCESS - {total} entries added to {file_path}!!!")
|
||||
logger.info(f"SUCCESS - {total} entries added to {file_path}!!!")
|
||||
return
|
||||
except: raise
|
||||
except:
|
||||
logger.exception()
|
||||
|
||||
|
||||
def delete_file(file_path, file_type):
|
||||
@@ -205,17 +211,17 @@ def delete_file(file_path, file_type):
|
||||
Deletes the directory or the file.
|
||||
"""
|
||||
if not check_existence(file_path, file_type):
|
||||
raise Exception(f"ERROR: Attempt to delete failed. {file_path} does not exist!!!")
|
||||
logger.exception(f"ERROR: Attempt to delete failed. {file_path} does not exist!!!")
|
||||
elif (file_type == "file"):
|
||||
os.remove(file_path)
|
||||
print(f"Successfully deleted {file_path}!!!")
|
||||
logger.info(f"Successfully deleted {file_path}!!!")
|
||||
return
|
||||
elif (file_type == "dir"):
|
||||
os.rmdir(file_path)
|
||||
print(f"Successfully deleted {file_path}!!!")
|
||||
logger.info(f"Successfully deleted {file_path}!!!")
|
||||
return
|
||||
else:
|
||||
raise OSError(f"ERROR: {file_type} needs to be either 'file' or 'dir' !!!")
|
||||
logger.exception(f"OSError: {file_type} needs to be either 'file' or 'dir' !!!")
|
||||
|
||||
|
||||
def clean_video_files(settings, tag, new_data=None):
|
||||
@@ -228,10 +234,8 @@ def clean_video_files(settings, tag, new_data=None):
|
||||
for file in new_data:
|
||||
settings["videos_from"] = settings['data'] + f"/{tag}/videos/#{tag}/{file}.mp4"
|
||||
shutil.move(settings['videos_from'], settings['videos_to'])
|
||||
#subprocess.call(f"mv {settings['videos_from']} {settings['videos_to']}", shell=True)
|
||||
|
||||
shutil.rmtree(settings['videos_delete'])
|
||||
#subprocess.call(f"rm -rf {settings['videos_delete']}", shell=True)
|
||||
print(f"Successfully deleted the folder {settings['videos_delete']} folder of videos.")
|
||||
logger.info(f"Successfully deleted the folder {settings['videos_delete']} folder of videos.")
|
||||
except:
|
||||
raise
|
||||
|
||||
@@ -6,7 +6,6 @@ Contains global constants relating to paths and operational parameters such as s
|
||||
# Directories
|
||||
DATA = "../data"
|
||||
IDS = "ids"
|
||||
LOG = "log"
|
||||
POSTS = "posts"
|
||||
VIDEOS = "videos"
|
||||
IMAGES = f"{DATA}/img"
|
||||
@@ -15,13 +14,11 @@ IMAGES = f"{DATA}/img"
|
||||
POST_IDS = "post_ids.json"
|
||||
VIDEO_IDS = "video_ids.json"
|
||||
DATA_FILE = "data.json"
|
||||
LOG_FILE = "log.json"
|
||||
|
||||
|
||||
FILES = {
|
||||
"data" : DATA,
|
||||
"ids" : IDS,
|
||||
"log" : LOG,
|
||||
"posts" : POSTS,
|
||||
"videos" : VIDEOS,
|
||||
"images" : IMAGES,
|
||||
@@ -29,7 +26,6 @@ FILES = {
|
||||
"video_ids" : f"{DATA}/{IDS}/{VIDEO_IDS}",
|
||||
"data_file" : f"{DATA_FILE}",
|
||||
"downloads" : [],
|
||||
"logger" : f"{DATA}/{LOG}/{LOG_FILE}",
|
||||
}
|
||||
|
||||
|
||||
|
||||
@@ -3,16 +3,15 @@ import json
|
||||
import argparse
|
||||
import matplotlib.pyplot as plt
|
||||
from datetime import datetime
|
||||
from file_methods import check_file
|
||||
from global_data import IMAGES
|
||||
|
||||
|
||||
"""
|
||||
Plots the frequency of hashtags appearing in the set of given posts.
|
||||
"""
|
||||
|
||||
|
||||
sys.path.insert(0, '../tiktok_downloader')
|
||||
import file_methods, global_data
|
||||
|
||||
|
||||
|
||||
def get_hashtags(obj):
|
||||
if not obj:
|
||||
@@ -98,8 +97,8 @@ if __name__ == "__main__":
|
||||
|
||||
The function get_occurrences is triggered to compute and return the top n occurrences and the hashtags.
|
||||
"""
|
||||
img_folder = global_data.IMAGES
|
||||
file_methods.check_file(img_folder, "dir")
|
||||
img_folder = IMAGES
|
||||
check_file(img_folder, "dir")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("input_file", help="The json hashtag file name")
|
||||
parser.add_argument("n", help="The number of top n occurrences", type=int)
|
||||
@@ -6,6 +6,13 @@ import global_data
|
||||
import file_methods
|
||||
import data_methods
|
||||
|
||||
# setting up the logging
|
||||
import logging
|
||||
from logging.config import fileConfig
|
||||
|
||||
fileConfig('../logging.ini')
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
"""
|
||||
The run_downloader.py dowloads data using the tiktok-scraper (https://github.com/drawrowfly/tiktok-scraper).
|
||||
@@ -47,8 +54,8 @@ def get_hashtag_list(file_name):
|
||||
with open(file_name) as f:
|
||||
tags = list(filter(None, [line.strip() for line in f if not line.startswith("#")]))
|
||||
return tags
|
||||
except IOError as error:
|
||||
print(error)
|
||||
except IOError:
|
||||
logger.exception(f"IOError")
|
||||
|
||||
|
||||
def create_parser():
|
||||
@@ -72,12 +79,9 @@ def set_download_settings(download_data_type):
|
||||
settings = {}
|
||||
settings["data"] = global_data.FILES["data"]
|
||||
settings["ids"] = global_data.FILES["ids"]
|
||||
settings["log"] = global_data.FILES["log"]
|
||||
settings["logger"] = global_data.FILES["logger"]
|
||||
settings["sleep"] = global_data.PARAMETERS["sleep"]
|
||||
settings["scraper"] = global_data.PARAMETERS["scraper_attempts"]
|
||||
file_methods.check_file(f"{settings['data']}/{settings['ids']}", "dir")
|
||||
file_methods.check_file(f"{settings['data']}/{settings['log']}", "dir")
|
||||
if download_data_type["posts"]:
|
||||
settings["posts"] = global_data.FILES["posts"]
|
||||
settings["post_ids"] = global_data.FILES["post_ids"]
|
||||
@@ -195,7 +199,7 @@ if __name__ == "__main__":
|
||||
|
||||
print(hashtags)
|
||||
if not hashtags:
|
||||
raise Exception("No hashtags were given, please use either -t option or -f to provide hashtags.")
|
||||
logger.exception("No hashtags were given, please use either -t option or -f to provide hashtags.")
|
||||
|
||||
if (args.p and args.v):
|
||||
download_data_type = {
|
||||
@@ -218,4 +222,4 @@ if __name__ == "__main__":
|
||||
if log_data:
|
||||
file_methods.log_writer(log_data)
|
||||
except:
|
||||
raise
|
||||
logger.exception(f"ERROR")
|
||||
|
||||
Reference in New Issue
Block a user