From a4d58b73242eead5b2c037d2fd00a572de597171 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:21:58 +0200
Subject: [PATCH 01/24] Update run_downloader.py
---
tiktok_downloader/run_downloader.py | 22 ++++++++++++++--------
1 file changed, 14 insertions(+), 8 deletions(-)
diff --git a/tiktok_downloader/run_downloader.py b/tiktok_downloader/run_downloader.py
index d921bad..39b00ce 100644
--- a/tiktok_downloader/run_downloader.py
+++ b/tiktok_downloader/run_downloader.py
@@ -7,6 +7,15 @@ import global_data
import file_methods
import data_methods
+# setting up the logging
+import logging
+from logging.config import fileConfig
+
+fileConfig('../logging.ini')
+logger = logging.getLogger()
+
+
+
"""
The run_downloader.py dowloads data using the tiktok-scraper (https://github.com/drawrowfly/tiktok-scraper).
@@ -49,8 +58,8 @@ def get_hashtag_list(file_name):
gn = (line.strip() for line in f if not line.startswith("#"))
tags = list(line for line in gn if line)
return tags
- except IOError as error:
- print(error)
+ except IOError:
+ logger.exception(f"IOError")
def create_parser():
@@ -74,12 +83,9 @@ def set_download_settings(download_data_type):
settings = {}
settings["data"] = global_data.FILES["data"]
settings["ids"] = global_data.FILES["ids"]
- settings["log"] = global_data.FILES["log"]
- settings["logger"] = global_data.FILES["logger"]
settings["sleep"] = global_data.PARAMETERS["sleep"]
settings["scraper"] = global_data.PARAMETERS["scraper_attempts"]
file_methods.check_file(f"{settings['data']}/{settings['ids']}", "dir")
- file_methods.check_file(f"{settings['data']}/{settings['log']}", "dir")
if download_data_type["posts"]:
settings["posts"] = global_data.FILES["posts"]
settings["post_ids"] = global_data.FILES["post_ids"]
@@ -188,7 +194,7 @@ def get_hashtags(file_name, hashtag_list):
from hashtag_list import hashtag_list
return hashtag_list
except ImportError:
- raise ImportError(f"ERROR: something went wrong while reading the file {file_name}!")
+ logger.exception(f"ERROR: something went wrong while reading the file {file_name}!")
if __name__ == "__main__":
@@ -209,7 +215,7 @@ if __name__ == "__main__":
print(hashtags)
if not hashtags:
- raise Exception("No hashtags were given, please use either --h option or -f to provide hashtags.")
+ logger.exception(f"No hashtags were given, please use either --h option or -f to provide hashtags.")
if (args.p and args.v):
download_data_type = {
@@ -232,4 +238,4 @@ if __name__ == "__main__":
if log_data:
file_methods.log_writer(log_data)
except:
- raise
+ logger.exception(f"ERROR")
From 7bb3dbaa0ba7dcbe80b0d7eaf580918b3e42d921 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:22:29 +0200
Subject: [PATCH 02/24] Update data_methods.py
---
tiktok_downloader/data_methods.py | 85 +++++++++++++++++--------------
1 file changed, 48 insertions(+), 37 deletions(-)
diff --git a/tiktok_downloader/data_methods.py b/tiktok_downloader/data_methods.py
index d1cbb5b..a6f62e6 100644
--- a/tiktok_downloader/data_methods.py
+++ b/tiktok_downloader/data_methods.py
@@ -4,12 +4,22 @@ from datetime import datetime
import global_data
import file_methods
+# setting up the logging
+import logging
+from logging.config import fileConfig
+
+fileConfig('../logging.ini')
+logger = logging.getLogger()
+
+
+
+
"""
The file contains several functions that perform data processing related tasks.
"""
-difference = namedtuple("difference", "new_ids size")
+diff = namedtuple("difference", "ids filter_posts")
total = namedtuple("total", "total unique")
@@ -18,23 +28,29 @@ def get_difference(tag, file, ids):
Compares two sets of ids and returns the difference of the two sets.
Purpose - user to filter out the new ids by comparing the set of id list (ids/post_ids.json or videos_ids.json) and the list of newly downloaded ids.
"""
- maiden_entry = False
+ filter_posts = False
current_id_data = file_methods.get_data(file)
if tag in current_id_data:
current_ids = current_id_data[tag]
- set1 = set(current_ids)
- set2 = set(ids)
- new_ids = set2.difference(set1)
- if new_ids:
- new_ids = list(new_ids)
- size = len(new_ids)
- diff = difference(new_ids, size)
- return (diff, maiden_entry)
+ set_current_ids = set(current_ids)
+ total_current_ids = len(set_current_ids)
+ set_ids = set(ids)
+ new_ids = set_ids.difference(set_current_ids)
+ if not new_ids:
+ return
else:
- return ([], maiden_entry)
- else:
- maiden_entry = True
- return (ids, maiden_entry)
+ new_ids = list(new_ids)
+ total_new_ids = len(new_ids)
+ if total_new_ids == total_current_ids:
+ filter_posts = False
+ new_data = diff(new_ids, filter_posts)
+ else:
+ new_data = diff(new_ids, filter_posts)
+ return new_data
+ else:
+ filter_posts = True
+ new_data = diff(ids, filter_posts)
+ return new_data
def extract_posts(settings, file_name, tag):
@@ -43,13 +59,13 @@ def extract_posts(settings, file_name, tag):
"""
ids = []
posts = []
- new_posts = []
posts = file_methods.get_data(file_name)
for post in posts:
ids.append(post["id"])
+
if not ids:
- print(f"WARNING: no posts were found for {tag} in the file - {file_name}")
+ logger.warn(f"WARNING: no posts were found for {tag} in the file - {file_name}")
return
status = file_methods.check_existence(settings["post_ids"], "file")
@@ -57,18 +73,17 @@ def extract_posts(settings, file_name, tag):
new_data = (ids, posts)
return new_data
else:
- res = get_difference(tag, settings["post_ids"], ids)
- if res[1]:
- new_data = (ids, posts)
+ new_ids = get_difference(tag, settings["post_ids"], ids)
+ if not new_ids:
+ logger.warn(f"WARNING: No new posts were found in the downloaded file - {file_name}")
+ return
+ elif new_ids.filter_posts:
+ new_posts = [ post for post in posts if post['id'] in new_ids.ids ]
+ new_data = (new_ids.ids, new_posts)
return new_data
else:
- if res[0]:
- new_posts = [ post for post in posts if posts['id'] in res[0].new_ids ]
- new_data = (res[0].new_ids, new_posts)
- return new_data
- else:
- print(f"WARNING: No new posts were found in the downloaded file - {file_name}")
- return
+ new_data = (new_ids.ids, new_posts)
+ return new_data
def extract_videos(settings, tag, download_list):
@@ -80,16 +95,12 @@ def extract_videos(settings, tag, download_list):
new_data = download_list
return new_data
else:
- res = get_difference(tag, settings["video_ids"], download_list)
- if res[1]:
- return download_list
+ new_videos = get_difference(tag, settings["video_ids"], download_list)
+ if not new_videos:
+ logger.warn(f"WARNING: No new videos were found for the {tag} in the downloaded folder.")
+ return
else:
- if res[0]:
- new_data = res[0].new_ids
- return new_data
- else:
- print(f"WARNING: No new videos were found for the {tag} in the downloaded folder.")
- return
+ return new_videos.ids
def update_posts(file_path, file_type, new_data, tag=None):
@@ -139,8 +150,8 @@ def print_total(file_path, tag, data_type):
"""
total = get_total_posts(file_path, tag)
if (total.total == total.unique):
- print(f"Total {data_type} for the hashtag {tag} are: {total.total}")
+ logger.info(f"Total {data_type} for the hashtag {tag} are: {total.total}")
return
else:
- print(f"WARNING: out of total {data_type} for the hashtag {tag} {total.total}, only {total.unique} are unique. Something is going wrong...")
+ logger.warn(f"WARNING: out of total {data_type} for the hashtag {tag} {total.total}, only {total.unique} are unique. Something is going wrong...")
return
From 8e6630f3626d63456ac3f6e3f1ffed82eef46d1a Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:22:58 +0200
Subject: [PATCH 03/24] Update file_methods.py
---
tiktok_downloader/file_methods.py | 60 ++++++++++++++++---------------
1 file changed, 32 insertions(+), 28 deletions(-)
diff --git a/tiktok_downloader/file_methods.py b/tiktok_downloader/file_methods.py
index 4a17cb2..5d27c27 100644
--- a/tiktok_downloader/file_methods.py
+++ b/tiktok_downloader/file_methods.py
@@ -4,6 +4,15 @@ import global_data
import shutil
+# setting up the logging
+import logging
+from logging.config import fileConfig
+
+fileConfig('../logging.ini')
+logger = logging.getLogger()
+
+
+
"""
The file contains the functions that operate on files, such as writing or reading from files etc.
"""
@@ -18,7 +27,7 @@ def create_file(name, file_type):
elif (file_type == "file"):
with open(name, "w"): pass
else:
- raise OSError(f"{file_type} has to be a 'dir' or a 'file'!!!")
+ logger.exception(f"{file_type} has to be a 'dir' or a 'file'!!!")
return
@@ -31,7 +40,7 @@ def check_existence(file_path, file_type):
elif (file_type == "dir"):
return os.path.isdir(file_path)
else:
- raise OSError(f"{file_type} has to be a 'dir' or a 'file'!!!")
+ logger.exception(f"{file_type} has to be a 'dir' or a 'file'!!!")
def check_file(file_path, file_type):
@@ -62,12 +71,12 @@ def download_posts(settings, tag):
os.chdir("../../../tiktok_downloader")
return new_file
else:
- print(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
+ logger.warn(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
os.chdir("../../../tiktok_downloader")
return
else:
os.chdir("../../../tiktok_downloader")
- print(f"WARNING: No file was downloaded by the tiktok-scraper for the {tag} !!!!")
+ logger.warn(f"WARNING: No file was downloaded by the tiktok-scraper for the {tag} !!!!")
return
except: raise
@@ -96,13 +105,13 @@ def download_videos(settings, tag):
os.chdir("../../../tiktok_downloader")
return downloaded_list
else:
- print(f"WARNING: No video files were downloaded for the hashtag {tag}.")
+ logger.warn(f"WARNING: No video files were downloaded for the hashtag {tag}.")
os.chdir("../../../tiktok_downloader")
shutil.rmtree(settings['videos_delete'])
#subprocess.call(f"rm -rf {settings['videos_delete']}", shell=True)
else:
os.chdir("../../../tiktok_downloader")
- print(f"WARNING: Something went wrong with the tiktok-scraper video download for the {tag} !!!!")
+ logger.warn(f"WARNING: Something went wrong with the tiktok-scraper video download for the {tag} !!!!")
return
except: raise
@@ -145,20 +154,15 @@ def log_writer(log_data):
log_dict[ele[0]] = { ele[1][0] : ele[1][1] }
total += ele[1][1]
- logger = global_data.FILES["logger"]
now = datetime.now()
now_str = now.strftime("%d-%m-%Y %H:%M:%S")
- status = check_existence(logger, "file")
- if status:
- data = get_data(logger)
- data[now_str] = log_dict
- dump_data(logger, data)
- else:
- data = { now_str : log_dict }
- dump_data(logger, data)
- print(f"Successfully logged {total} entries!!!!")
+ data = { now_str : log_dict }
+
+ logger.warn(data)
+ logger.info(f"Successfully logged {total} entries!!!!")
return
- except: raise
+ except:
+ logger.exception()
def id_writer(file_path, new_data, tag, status):
@@ -181,10 +185,11 @@ def id_writer(file_path, new_data, tag, status):
else:
data = { tag : new_data }
dump_data(file_path, data)
- print(f"SUCCESS - {total} entries added to {file_path}!!!")
+ logger.info(f"SUCCESS - {total} entries added to {file_path}!!!")
log_data = (tag, total)
return log_data
- except: raise
+ except:
+ logger.exception()
def post_writer(file_path, new_data, status):
@@ -204,9 +209,10 @@ def post_writer(file_path, new_data, status):
else:
data = new_data
dump_data(file_path, data)
- print(f"SUCCESS - {total} entries added to {file_path}!!!")
+ logger.info(f"SUCCESS - {total} entries added to {file_path}!!!")
return
- except: raise
+ except:
+ logger.exception()
def delete_file(file_path, file_type):
@@ -214,17 +220,17 @@ def delete_file(file_path, file_type):
Deletes the directory or the file.
"""
if not check_existence(file_path, file_type):
- raise Exception(f"ERROR: Attempt to delete failed. {file_path} does not exist!!!")
+ logger.exception(f"ERROR: Attempt to delete failed. {file_path} does not exist!!!")
elif (file_type == "file"):
os.remove(file_path)
- print(f"Successfully deleted {file_path}!!!")
+ logger.info(f"Successfully deleted {file_path}!!!")
return
elif (file_type == "dir"):
os.rmdir(file_path)
- print(f"Successfully deleted {file_path}!!!")
+ logger.info(f"Successfully deleted {file_path}!!!")
return
else:
- raise OSError(f"ERROR: {file_type} needs to be either 'file' or 'dir' !!!")
+ logger.exception(f"OSError: {file_type} needs to be either 'file' or 'dir' !!!")
def clean_video_files(settings, tag, new_data=None):
@@ -237,10 +243,8 @@ def clean_video_files(settings, tag, new_data=None):
for file in new_data:
settings["videos_from"] = settings['data'] + f"/{tag}/videos/#{tag}/{file}.mp4"
shutil.move(settings['videos_from'], settings['videos_to'])
- #subprocess.call(f"mv {settings['videos_from']} {settings['videos_to']}", shell=True)
shutil.rmtree(settings['videos_delete'])
- #subprocess.call(f"rm -rf {settings['videos_delete']}", shell=True)
- print(f"Successfully deleted the folder {settings['videos_delete']} folder of videos.")
+ logger.info(f"Successfully deleted the folder {settings['videos_delete']} folder of videos.")
except:
raise
From 6c864f5311480f78df5f58f92334a80435581b67 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:23:31 +0200
Subject: [PATCH 04/24] Update global_data.py
---
tiktok_downloader/global_data.py | 4 ----
1 file changed, 4 deletions(-)
diff --git a/tiktok_downloader/global_data.py b/tiktok_downloader/global_data.py
index 57df4f1..8c30ec3 100644
--- a/tiktok_downloader/global_data.py
+++ b/tiktok_downloader/global_data.py
@@ -6,7 +6,6 @@ Contains global constants relating to paths and operational parameters such as s
# Directories
DATA = "../data"
IDS = "ids"
-LOG = "log"
POSTS = "posts"
VIDEOS = "videos"
IMAGES = f"{DATA}/img"
@@ -15,13 +14,11 @@ IMAGES = f"{DATA}/img"
POST_IDS = "post_ids.json"
VIDEO_IDS = "video_ids.json"
DATA_FILE = "data.json"
-LOG_FILE = "log.json"
FILES = {
"data" : DATA,
"ids" : IDS,
- "log" : LOG,
"posts" : POSTS,
"videos" : VIDEOS,
"images" : IMAGES,
@@ -29,7 +26,6 @@ FILES = {
"video_ids" : f"{DATA}/{IDS}/{VIDEO_IDS}",
"data_file" : f"{DATA_FILE}",
"downloads" : [],
- "logger" : f"{DATA}/{LOG}/{LOG_FILE}",
}
From 905f524e11591329dff1f378081e2007086e8678 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:24:34 +0200
Subject: [PATCH 05/24] Delete analytics directory
---
analytics/hashtag_frequencies.py | 123 -------------------------------
analytics/logging_analytics.py | 4 -
2 files changed, 127 deletions(-)
delete mode 100644 analytics/hashtag_frequencies.py
delete mode 100644 analytics/logging_analytics.py
diff --git a/analytics/hashtag_frequencies.py b/analytics/hashtag_frequencies.py
deleted file mode 100644
index 2ded3d1..0000000
--- a/analytics/hashtag_frequencies.py
+++ /dev/null
@@ -1,123 +0,0 @@
-import os, sys
-import csv, json
-import argparse
-import matplotlib.pyplot as plt
-from datetime import datetime
-
-"""
-Plots the frequency of hashtags appearing in the set of given posts.
-"""
-
-
-sys.path.insert(0, '../tiktok_downloader')
-import file_methods, global_data
-
-
-
-def get_hashtags(obj):
- if not obj:
- print(f'ERROR: Empty item, no hashtags to be extracted.')
- return
- else:
- hashtags = {}
- tags = [ [tag['name'] for tag in ele['hashtags']] for ele in obj ]
- tags = [ set(ele) for ele in tags ]
- { tag: (1 if tag not in hashtags and not hashtags.update({tag: 1})
- else hashtags[tag] + 1 and not hashtags.update({tag: hashtags[tag] + 1}))
- for ele in tags for tag in ele }
- hashtags = sorted(hashtags.items(), key=lambda e: e[1], reverse=True)
-
- return hashtags
-
-
-def get_occurrences(filename, n=1 , sort=True):
- """
- Takes the json file containing posts and returns a dictionary:
- local variable occs = {
- "total": total posts in the file,
- top_n: [[top n hashtags ], [frequencies of corresponding hashtags]]
- }
- """
- with open(filename) as f:
- obj = json.load(f)
- l = len(obj)
- tags = get_hashtags(obj)
- occs = {
- "total": l,
- "top_n": []
- }
- occs["top_n"] = [ [ ele[i] for ele in tags[0:n] ] for i in range(2)]
- return occs
-
-
-def plot(n, occs, img_folder):
- plt.scatter(occs["top_n"][0], occs["top_n"][1])
- plt.tight_layout()
- plt.xticks(rotation=45)
- plt.title(f'Hashtag Distribution')
- plt.xlabel(f'Top {n} hashtags from {occs["total"]} posts.')
- plt.ylabel(f'Number of occurrences')
- save_plot(img_folder)
- plt.show(block=None)
- return
-
-
-def print_occurrences(occs):
- """
- Prints the top n hashtags with their frequencies and the ratio of occurrences and total posts, all to the shell.
- """
- row_number = 0
- total_posts = occs["total"]
- print ("{:<8} {:<15} {:<15} {:<15}".format("Rank", 'Hashtag','Occurrences',f'Frequency (Occurrences/Total-Posts(total_posts))'))
- for key,value in zip(occs["top_n"][0], occs["top_n"][1]):
- ratio = value/total_posts
- print ("{:<8} {:<15} {:<15} {:<15}".format(row_number, key, value, ratio))
- row_number += 1
- return
-
-
-def save_plot(img_folder):
- """
- Saves the plot to a png file in the folder /data/imgs/
- """
- try:
- now = datetime.now()
- current_time = now.strftime("%Y_%m_%d_%H_%M_%S")
- plt.savefig(f"{img_folder}/{current_time}.png")
-
- return
- except: raise
-
-
-
-if __name__ == "__main__":
- """
- Option "n" specifies how many hashtags does the user wants to plot.
- "-d" option prints the hashtag frequencies on the shell
- "-p" option plots the hashtag frequencies and saves as a png file in the folder /data/imgs/
-
- The function get_occurances is triggered to compute and return the top n occurances and the hashtags.
- """
- img_folder = global_data.IMAGES
- file_methods.check_file(img_folder, "dir")
- parser = argparse.ArgumentParser()
- parser.add_argument("input_file", help="The json hashtag file name")
- parser.add_argument("n", help="The number of top n occurrences", type=int)
- parser.add_argument("-p", "--plot", help="Plot the occurrences", action="store_true")
- parser.add_argument("-d", "--print", help="List top n hashtags", action="store_true")
- args = parser.parse_args()
- if args.input_file and args.n:
- if args.n < 1:
- print(f"Please make sure the number of top occurrences is a positive integer.")
- sys.exit()
-
- base = os.path.splitext(args.input_file)[0]
- path = f"./{base}_sorted_hashtags.csv"
- if args.plot:
- occs = get_occurrences(args.input_file, args.n)
- plot(args.n, occs, img_folder)
- else:
- occs = get_occurrences(args.input_file, args.n)
- print_occurrences(occs)
- else:
- print(f'ERROR: either {args.input_file} or {args.n} or both contains error.')
diff --git a/analytics/logging_analytics.py b/analytics/logging_analytics.py
deleted file mode 100644
index cba8ca5..0000000
--- a/analytics/logging_analytics.py
+++ /dev/null
@@ -1,4 +0,0 @@
-"""
-Yet to be written ...
-"""
-
From a55a9ffc1d72b842a7470517defced2670c9771c Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:24:58 +0200
Subject: [PATCH 06/24] Add files via upload
---
tiktok_downloader/hashtag_frequencies.py | 122 +++++++++++++++++++++++
1 file changed, 122 insertions(+)
create mode 100644 tiktok_downloader/hashtag_frequencies.py
diff --git a/tiktok_downloader/hashtag_frequencies.py b/tiktok_downloader/hashtag_frequencies.py
new file mode 100644
index 0000000..3f9a07f
--- /dev/null
+++ b/tiktok_downloader/hashtag_frequencies.py
@@ -0,0 +1,122 @@
+import os, sys
+import csv, json
+import argparse
+import matplotlib.pyplot as plt
+from datetime import datetime
+from file_methods import check_file
+from global_data import IMAGES
+
+
+"""
+Plots the frequency of hashtags appearing in the set of given posts.
+"""
+
+
+
+def get_hashtags(obj):
+ if not obj:
+ print(f'ERROR: Empty item, no hashtags to be extracted.')
+ return
+ else:
+ hashtags = {}
+ tags = [ [tag['name'] for tag in ele['hashtags']] for ele in obj ]
+ tags = [ set(ele) for ele in tags ]
+ { tag: (1 if tag not in hashtags and not hashtags.update({tag: 1})
+ else hashtags[tag] + 1 and not hashtags.update({tag: hashtags[tag] + 1}))
+ for ele in tags for tag in ele }
+ hashtags = sorted(hashtags.items(), key=lambda e: e[1], reverse=True)
+
+ return hashtags
+
+
+def get_occurrences(filename, n=1 , sort=True):
+ """
+ Takes the json file containing posts and returns a dictionary:
+ local variable occs = {
+ "total": total posts in the file,
+ top_n: [[top n hashtags ], [frequencies of corresponding hashtags]]
+ }
+ """
+ with open(filename) as f:
+ obj = json.load(f)
+ l = len(obj)
+ tags = get_hashtags(obj)
+ occs = {
+ "total": l,
+ "top_n": []
+ }
+ occs["top_n"] = [ [ ele[i] for ele in tags[0:n] ] for i in range(2)]
+ return occs
+
+
+def plot(n, occs, img_folder):
+ plt.scatter(occs["top_n"][0], occs["top_n"][1])
+ plt.tight_layout()
+ plt.xticks(rotation=45)
+ plt.title(f'Hashtag Distribution')
+ plt.xlabel(f'Top {n} hashtags from {occs["total"]} posts.')
+ plt.ylabel(f'Number of occurrences')
+ save_plot(img_folder)
+ plt.show(block=None)
+ return
+
+
+def print_occurrences(occs):
+ """
+ Prints the top n hashtags with their frequencies and the ratio of occurrences and total posts, all to the shell.
+ """
+ row_number = 0
+ total_posts = occs["total"]
+ print ("{:<8} {:<15} {:<15} {:<15}".format("Rank", 'Hashtag','Occurrences',f'Frequency (Occurrences/Total-Posts(total_posts))'))
+ for key,value in zip(occs["top_n"][0], occs["top_n"][1]):
+ ratio = value/total_posts
+ print ("{:<8} {:<15} {:<15} {:<15}".format(row_number, key, value, ratio))
+ row_number += 1
+ return
+
+
+def save_plot(img_folder):
+ """
+ Saves the plot to a png file in the folder /data/imgs/
+ """
+ try:
+ now = datetime.now()
+ current_time = now.strftime("%Y_%m_%d_%H_%M_%S")
+ plt.savefig(f"{img_folder}/{current_time}.png")
+
+ return
+ except: raise
+
+
+
+if __name__ == "__main__":
+ """
+ Option "n" specifies how many hashtags does the user wants to plot.
+ "-d" option prints the hashtag frequencies on the shell
+ "-p" option plots the hashtag frequencies and saves as a png file in the folder /data/imgs/
+
+ The function get_occurances is triggered to compute and return the top n occurances and the hashtags.
+ """
+ img_folder = IMAGES
+ check_file(img_folder, "dir")
+ parser = argparse.ArgumentParser()
+ parser.add_argument("input_file", help="The json hashtag file name")
+ parser.add_argument("n", help="The number of top n occurrences", type=int)
+ parser.add_argument("-p", "--plot", help="Plot the occurrences", action="store_true")
+ parser.add_argument("-d", "--print", help="List top n hashtags", action="store_true")
+ args = parser.parse_args()
+ if args.input_file and args.n:
+ if args.n < 1:
+ print(f"Please make sure the number of top occurrences is a positive integer.")
+ sys.exit()
+
+ base = os.path.splitext(args.input_file)[0]
+ path = f"./{base}_sorted_hashtags.csv"
+ if args.plot:
+ occs = get_occurrences(args.input_file, args.n)
+ plot(args.n, occs, img_folder)
+ else:
+ occs = get_occurrences(args.input_file, args.n)
+ print_occurrences(occs)
+ else:
+ print(f'ERROR: either {args.input_file} or {args.n} or both contains error.')
From 2d212a972137d72de662c9359609be3152c8236c Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:25:23 +0200
Subject: [PATCH 07/24] Delete Pipfile
---
Pipfile | 12 ------------
1 file changed, 12 deletions(-)
delete mode 100644 Pipfile
diff --git a/Pipfile b/Pipfile
deleted file mode 100644
index 4a93470..0000000
--- a/Pipfile
+++ /dev/null
@@ -1,12 +0,0 @@
-[[source]]
-url = "https://pypi.python.org/simple"
-verify_ssl = true
-name = "pypi"
-
-[packages]
-
-[dev-packages]
-pylint = "*"
-
-[requires]
-python_version = "3.6+"
From 1c395b513c26893afe18a441ce6bf61003dd21f6 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:25:30 +0200
Subject: [PATCH 08/24] Delete Pipfile.lock
---
Pipfile.lock | 170 ---------------------------------------------------
1 file changed, 170 deletions(-)
delete mode 100644 Pipfile.lock
diff --git a/Pipfile.lock b/Pipfile.lock
deleted file mode 100644
index 58fc6ff..0000000
--- a/Pipfile.lock
+++ /dev/null
@@ -1,170 +0,0 @@
-{
- "_meta": {
- "hash": {
- "sha256": "54bb714adcfa14c627d84696f321a9d68f7400cdef871098e6f49c81d854b478"
- },
- "pipfile-spec": 6,
- "requires": {
- "python_version": "3.6+"
- },
- "sources": [
- {
- "name": "pypi",
- "url": "https://pypi.python.org/simple",
- "verify_ssl": true
- }
- ]
- },
- "default": {},
- "develop": {
- "astroid": {
- "hashes": [
- "sha256:1efdf4e867d4d8ba4a9f6cf9ce07cd182c4c41de77f23814feb27ca93ca9d877",
- "sha256:506daabe5edffb7e696ad82483ad0228245a9742ed7d2d8c9cdb31537decf9f6"
- ],
- "version": "==2.9.3"
- },
- "isort": {
- "hashes": [
- "sha256:6f62d78e2f89b4500b080fe3a81690850cd254227f27f75c3a0c491a1f351ba7",
- "sha256:e8443a5e7a020e9d7f97f1d7d9cd17c88bcb3bc7e218bf9cf5095fe550be2951"
- ],
- "version": "==5.10.1"
- },
- "lazy-object-proxy": {
- "hashes": [
- "sha256:043651b6cb706eee4f91854da4a089816a6606c1428fd391573ef8cb642ae4f7",
- "sha256:07fa44286cda977bd4803b656ffc1c9b7e3bc7dff7d34263446aec8f8c96f88a",
- "sha256:12f3bb77efe1367b2515f8cb4790a11cffae889148ad33adad07b9b55e0ab22c",
- "sha256:2052837718516a94940867e16b1bb10edb069ab475c3ad84fd1e1a6dd2c0fcfc",
- "sha256:2130db8ed69a48a3440103d4a520b89d8a9405f1b06e2cc81640509e8bf6548f",
- "sha256:39b0e26725c5023757fc1ab2a89ef9d7ab23b84f9251e28f9cc114d5b59c1b09",
- "sha256:46ff647e76f106bb444b4533bb4153c7370cdf52efc62ccfc1a28bdb3cc95442",
- "sha256:4dca6244e4121c74cc20542c2ca39e5c4a5027c81d112bfb893cf0790f96f57e",
- "sha256:553b0f0d8dbf21890dd66edd771f9b1b5f51bd912fa5f26de4449bfc5af5e029",
- "sha256:677ea950bef409b47e51e733283544ac3d660b709cfce7b187f5ace137960d61",
- "sha256:6a24357267aa976abab660b1d47a34aaf07259a0c3859a34e536f1ee6e76b5bb",
- "sha256:6a6e94c7b02641d1311228a102607ecd576f70734dc3d5e22610111aeacba8a0",
- "sha256:6aff3fe5de0831867092e017cf67e2750c6a1c7d88d84d2481bd84a2e019ec35",
- "sha256:6ecbb350991d6434e1388bee761ece3260e5228952b1f0c46ffc800eb313ff42",
- "sha256:7096a5e0c1115ec82641afbdd70451a144558ea5cf564a896294e346eb611be1",
- "sha256:70ed0c2b380eb6248abdef3cd425fc52f0abd92d2b07ce26359fcbc399f636ad",
- "sha256:8561da8b3dd22d696244d6d0d5330618c993a215070f473b699e00cf1f3f6443",
- "sha256:85b232e791f2229a4f55840ed54706110c80c0a210d076eee093f2b2e33e1bfd",
- "sha256:898322f8d078f2654d275124a8dd19b079080ae977033b713f677afcfc88e2b9",
- "sha256:8f3953eb575b45480db6568306893f0bd9d8dfeeebd46812aa09ca9579595148",
- "sha256:91ba172fc5b03978764d1df5144b4ba4ab13290d7bab7a50f12d8117f8630c38",
- "sha256:9d166602b525bf54ac994cf833c385bfcc341b364e3ee71e3bf5a1336e677b55",
- "sha256:a57d51ed2997e97f3b8e3500c984db50a554bb5db56c50b5dab1b41339b37e36",
- "sha256:b9e89b87c707dd769c4ea91f7a31538888aad05c116a59820f28d59b3ebfe25a",
- "sha256:bb8c5fd1684d60a9902c60ebe276da1f2281a318ca16c1d0a96db28f62e9166b",
- "sha256:c19814163728941bb871240d45c4c30d33b8a2e85972c44d4e63dd7107faba44",
- "sha256:c4ce15276a1a14549d7e81c243b887293904ad2d94ad767f42df91e75fd7b5b6",
- "sha256:c7a683c37a8a24f6428c28c561c80d5f4fd316ddcf0c7cab999b15ab3f5c5c69",
- "sha256:d609c75b986def706743cdebe5e47553f4a5a1da9c5ff66d76013ef396b5a8a4",
- "sha256:d66906d5785da8e0be7360912e99c9188b70f52c422f9fc18223347235691a84",
- "sha256:dd7ed7429dbb6c494aa9bc4e09d94b778a3579be699f9d67da7e6804c422d3de",
- "sha256:df2631f9d67259dc9620d831384ed7732a198eb434eadf69aea95ad18c587a28",
- "sha256:e368b7f7eac182a59ff1f81d5f3802161932a41dc1b1cc45c1f757dc876b5d2c",
- "sha256:e40f2013d96d30217a51eeb1db28c9ac41e9d0ee915ef9d00da639c5b63f01a1",
- "sha256:f769457a639403073968d118bc70110e7dce294688009f5c24ab78800ae56dc8",
- "sha256:fccdf7c2c5821a8cbd0a9440a456f5050492f2270bd54e94360cac663398739b",
- "sha256:fd45683c3caddf83abbb1249b653a266e7069a09f486daa8863fb0e7496a9fdb"
- ],
- "version": "==1.7.1"
- },
- "mccabe": {
- "hashes": [
- "sha256:ab8a6258860da4b6677da4bd2fe5dc2c659cff31b3ee4f7f5d64e79735b80d42",
- "sha256:dd8d182285a0fe56bace7f45b5e7d1a6ebcbf524e8f3bd87eb0f125271b8831f"
- ],
- "version": "==0.6.1"
- },
- "platformdirs": {
- "hashes": [
- "sha256:7535e70dfa32e84d4b34996ea99c5e432fa29a708d0f4e394bbcb2a8faa4f16d",
- "sha256:bcae7cab893c2d310a711b70b24efb93334febe65f8de776ee320b517471e227"
- ],
- "version": "==2.5.1"
- },
- "pylint": {
- "hashes": [
- "sha256:9d945a73640e1fec07ee34b42f5669b770c759acd536ec7b16d7e4b87a9c9ff9",
- "sha256:daabda3f7ed9d1c60f52d563b1b854632fd90035bcf01443e234d3dc794e3b74"
- ],
- "index": "pypi",
- "version": "==2.12.2"
- },
- "toml": {
- "hashes": [
- "sha256:806143ae5bfb6a3c6e736a764057db0e6a0e05e338b5630894a5f779cabb4f9b",
- "sha256:b3bda1d108d5dd99f4a20d24d9c348e91c4db7ab1b749200bded2f839ccbe68f"
- ],
- "version": "==0.10.2"
- },
- "typing-extensions": {
- "hashes": [
- "sha256:1a9462dcc3347a79b1f1c0271fbe79e844580bb598bafa1ed208b94da3cdcd42",
- "sha256:21c85e0fe4b9a155d0799430b0ad741cdce7e359660ccbd8b530613e8df88ce2"
- ],
- "markers": "python_version < '3.10'",
- "version": "==4.1.1"
- },
- "wrapt": {
- "hashes": [
- "sha256:086218a72ec7d986a3eddb7707c8c4526d677c7b35e355875a0fe2918b059179",
- "sha256:0877fe981fd76b183711d767500e6b3111378ed2043c145e21816ee589d91096",
- "sha256:0a017a667d1f7411816e4bf214646d0ad5b1da2c1ea13dec6c162736ff25a374",
- "sha256:0cb23d36ed03bf46b894cfec777eec754146d68429c30431c99ef28482b5c1df",
- "sha256:1fea9cd438686e6682271d36f3481a9f3636195578bab9ca3382e2f5f01fc185",
- "sha256:220a869982ea9023e163ba915077816ca439489de6d2c09089b219f4e11b6785",
- "sha256:25b1b1d5df495d82be1c9d2fad408f7ce5ca8a38085e2da41bb63c914baadff7",
- "sha256:2dded5496e8f1592ec27079b28b6ad2a1ef0b9296d270f77b8e4a3a796cf6909",
- "sha256:2ebdde19cd3c8cdf8df3fc165bc7827334bc4e353465048b36f7deeae8ee0918",
- "sha256:43e69ffe47e3609a6aec0fe723001c60c65305784d964f5007d5b4fb1bc6bf33",
- "sha256:46f7f3af321a573fc0c3586612db4decb7eb37172af1bc6173d81f5b66c2e068",
- "sha256:47f0a183743e7f71f29e4e21574ad3fa95676136f45b91afcf83f6a050914829",
- "sha256:498e6217523111d07cd67e87a791f5e9ee769f9241fcf8a379696e25806965af",
- "sha256:4b9c458732450ec42578b5642ac53e312092acf8c0bfce140ada5ca1ac556f79",
- "sha256:51799ca950cfee9396a87f4a1240622ac38973b6df5ef7a41e7f0b98797099ce",
- "sha256:5601f44a0f38fed36cc07db004f0eedeaadbdcec90e4e90509480e7e6060a5bc",
- "sha256:5f223101f21cfd41deec8ce3889dc59f88a59b409db028c469c9b20cfeefbe36",
- "sha256:610f5f83dd1e0ad40254c306f4764fcdc846641f120c3cf424ff57a19d5f7ade",
- "sha256:6a03d9917aee887690aa3f1747ce634e610f6db6f6b332b35c2dd89412912bca",
- "sha256:705e2af1f7be4707e49ced9153f8d72131090e52be9278b5dbb1498c749a1e32",
- "sha256:766b32c762e07e26f50d8a3468e3b4228b3736c805018e4b0ec8cc01ecd88125",
- "sha256:77416e6b17926d953b5c666a3cb718d5945df63ecf922af0ee576206d7033b5e",
- "sha256:778fd096ee96890c10ce96187c76b3e99b2da44e08c9e24d5652f356873f6709",
- "sha256:78dea98c81915bbf510eb6a3c9c24915e4660302937b9ae05a0947164248020f",
- "sha256:7dd215e4e8514004c8d810a73e342c536547038fb130205ec4bba9f5de35d45b",
- "sha256:7dde79d007cd6dfa65afe404766057c2409316135cb892be4b1c768e3f3a11cb",
- "sha256:81bd7c90d28a4b2e1df135bfbd7c23aee3050078ca6441bead44c42483f9ebfb",
- "sha256:85148f4225287b6a0665eef08a178c15097366d46b210574a658c1ff5b377489",
- "sha256:865c0b50003616f05858b22174c40ffc27a38e67359fa1495605f96125f76640",
- "sha256:87883690cae293541e08ba2da22cacaae0a092e0ed56bbba8d018cc486fbafbb",
- "sha256:8aab36778fa9bba1a8f06a4919556f9f8c7b33102bd71b3ab307bb3fecb21851",
- "sha256:8c73c1a2ec7c98d7eaded149f6d225a692caa1bd7b2401a14125446e9e90410d",
- "sha256:936503cb0a6ed28dbfa87e8fcd0a56458822144e9d11a49ccee6d9a8adb2ac44",
- "sha256:944b180f61f5e36c0634d3202ba8509b986b5fbaf57db3e94df11abee244ba13",
- "sha256:96b81ae75591a795d8c90edc0bfaab44d3d41ffc1aae4d994c5aa21d9b8e19a2",
- "sha256:981da26722bebb9247a0601e2922cedf8bb7a600e89c852d063313102de6f2cb",
- "sha256:ae9de71eb60940e58207f8e71fe113c639da42adb02fb2bcbcaccc1ccecd092b",
- "sha256:b73d4b78807bd299b38e4598b8e7bd34ed55d480160d2e7fdaabd9931afa65f9",
- "sha256:d4a5f6146cfa5c7ba0134249665acd322a70d1ea61732723c7d3e8cc0fa80755",
- "sha256:dd91006848eb55af2159375134d724032a2d1d13bcc6f81cd8d3ed9f2b8e846c",
- "sha256:e05e60ff3b2b0342153be4d1b597bbcfd8330890056b9619f4ad6b8d5c96a81a",
- "sha256:e6906d6f48437dfd80464f7d7af1740eadc572b9f7a4301e7dd3d65db285cacf",
- "sha256:e92d0d4fa68ea0c02d39f1e2f9cb5bc4b4a71e8c442207433d8db47ee79d7aa3",
- "sha256:e94b7d9deaa4cc7bac9198a58a7240aaf87fe56c6277ee25fa5b3aa1edebd229",
- "sha256:ea3e746e29d4000cd98d572f3ee2a6050a4f784bb536f4ac1f035987fc1ed83e",
- "sha256:ec7e20258ecc5174029a0f391e1b948bf2906cd64c198a9b8b281b811cbc04de",
- "sha256:ec9465dd69d5657b5d2fa6133b3e1e989ae27d29471a672416fd729b429eb554",
- "sha256:f122ccd12fdc69628786d0c947bdd9cb2733be8f800d88b5a37c57f1f1d73c10",
- "sha256:f99c0489258086308aad4ae57da9e8ecf9e1f3f30fa35d5e170b4d4896554d80",
- "sha256:f9c51d9af9abb899bd34ace878fbec8bf357b3194a10c4e8e0a25512826ef056",
- "sha256:fd76c47f20984b43d93de9a82011bb6e5f8325df6c9ed4d8310029a55fa361ea"
- ],
- "version": "==1.13.3"
- }
- }
-}
From 851d4b31ffa8c3592bf625a667f634d010d4e146 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:25:54 +0200
Subject: [PATCH 09/24] Add files via upload
---
logging.ini | 32 ++++++++++++++++++++++++++++++++
requirements.txt | 10 ++++++++++
2 files changed, 42 insertions(+)
create mode 100644 logging.ini
create mode 100644 requirements.txt
diff --git a/logging.ini b/logging.ini
new file mode 100644
index 0000000..d56122e
--- /dev/null
+++ b/logging.ini
@@ -0,0 +1,32 @@
+[loggers]
+keys=root
+
+[handlers]
+keys=consoleHandler,fileHandler
+
+[formatters]
+keys=consoleFormatter,fileFormatter
+
+[logger_root]
+level=INFO
+handlers=consoleHandler,fileHandler
+
+[handler_consoleHandler]
+class=StreamHandler
+level=DEBUG
+formatter=consoleFormatter
+args=(sys.stdout,)
+
+[handler_fileHandler]
+class=FileHandler
+level=WARNING
+formatter=fileFormatter
+args=("../logfile.log",)
+
+[formatter_fileFormatter]
+format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
+datefmt=
+
+[formatter_consoleFormatter]
+format=%(levelname)s - %(message)s
+datefmt=
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..3f38370
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,10 @@
+cycler==0.11.0
+fonttools==4.33.3
+kiwisolver==1.4.2
+matplotlib==3.5.2
+numpy==1.22.3
+packaging==21.3
+Pillow==9.1.0
+pyparsing==3.0.8
+python-dateutil==2.8.2
+six==1.16.0
From ed1c7cb6ee5fbaced5f4563c97916cb5334ed6c0 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:29:21 +0200
Subject: [PATCH 10/24] Update README.md
---
README.md | 2 ++
1 file changed, 2 insertions(+)
diff --git a/README.md b/README.md
index b32a7c6..2384d7f 100644
--- a/README.md
+++ b/README.md
@@ -4,6 +4,8 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
## Pre-requisites
1. Make sure you have python 3.6 or a later version installed.
2. Download and install TikTok scraper: https://github.com/drawrowfly/tiktok-scraper
+3. Run python3 -m venv env
+5. Run pip install -r requirements.txt
### Options for running run_downloader.py
From 81905dd5703ecd6756a60e4714fd5b9a59eb49c5 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:30:29 +0200
Subject: [PATCH 11/24] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 2384d7f..9d8e803 100644
--- a/README.md
+++ b/README.md
@@ -4,7 +4,7 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
## Pre-requisites
1. Make sure you have python 3.6 or a later version installed.
2. Download and install TikTok scraper: https://github.com/drawrowfly/tiktok-scraper
-3. Run python3 -m venv env
+3. Go to the project folder and run python3 -m venv env
5. Run pip install -r requirements.txt
### Options for running run_downloader.py
From 6d5ca21103aa6cfa4cd757e534ac24e0162e7938 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:32:22 +0200
Subject: [PATCH 12/24] Update README.md
---
README.md | 13 +++++++++++++
1 file changed, 13 insertions(+)
diff --git a/README.md b/README.md
index 9d8e803..f2665dc 100644
--- a/README.md
+++ b/README.md
@@ -14,6 +14,19 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
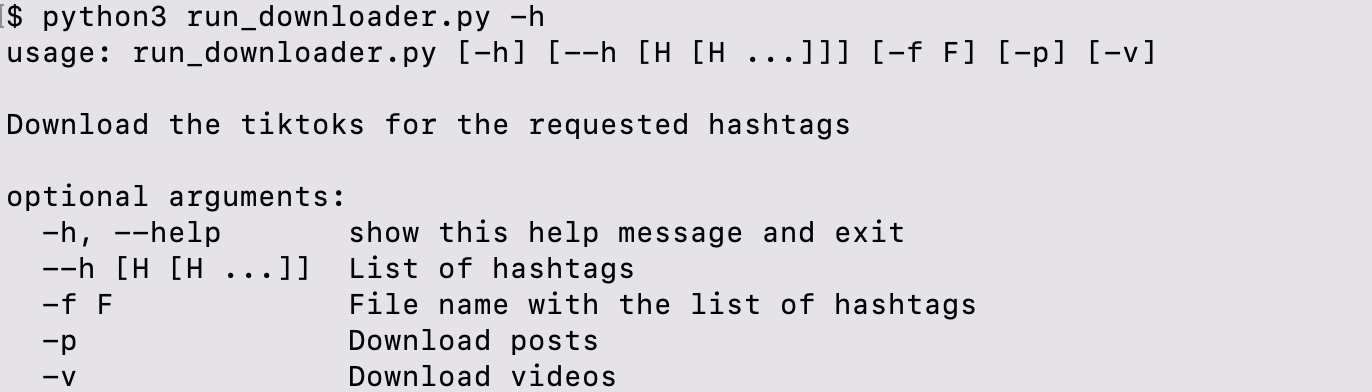 +$ python run_downloader.py -h
+usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
+
+Download the tiktoks for the requested hashtags
+
+optional arguments:
+-h, --help show this help message and exit
+-t [T [T ...]] List of hashtags
+-f F File name with the list of hashtags
+-p Download posts
+-v Download videos
+
+
### Data organization
From 63481427731e1be67bbdca0a06100a972522fb59 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:33:25 +0200
Subject: [PATCH 13/24] Update README.md
---
README.md | 29 +++++++++++++++++++----------
1 file changed, 19 insertions(+), 10 deletions(-)
diff --git a/README.md b/README.md
index f2665dc..2eb08ab 100644
--- a/README.md
+++ b/README.md
@@ -7,6 +7,25 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
3. Go to the project folder and run
+$ python run_downloader.py -h
+usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
+
+Download the tiktoks for the requested hashtags
+
+optional arguments:
+-h, --help show this help message and exit
+-t [T [T ...]] List of hashtags
+-f F File name with the list of hashtags
+-p Download posts
+-v Download videos
+
+
### Data organization
From 63481427731e1be67bbdca0a06100a972522fb59 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:33:25 +0200
Subject: [PATCH 13/24] Update README.md
---
README.md | 29 +++++++++++++++++++----------
1 file changed, 19 insertions(+), 10 deletions(-)
diff --git a/README.md b/README.md
index f2665dc..2eb08ab 100644
--- a/README.md
+++ b/README.md
@@ -7,6 +7,25 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
3. Go to the project folder and run python3 -m venv env
5. Run pip install -r requirements.txt
+
+
+
+ $ python run_downloader.py -h
+ usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
+
+ Download the tiktoks for the requested hashtags
+
+ optional arguments:
+ -h, --help show this help message and exit
+ -t [T [T ...]] List of hashtags
+ -f F File name with the list of hashtags
+ -p Download posts
+ -v Download videos
+
+
+
+
+
### Options for running run_downloader.py
python3 run_downloader.py -h
@@ -15,16 +34,6 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
$ python run_downloader.py -h
-usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
-
-Download the tiktoks for the requested hashtags
-
-optional arguments:
--h, --help show this help message and exit
--t [T [T ...]] List of hashtags
--f F File name with the list of hashtags
--p Download posts
--v Download videos
From 83d25faf3183adb4ed20f29e66f0f9b9e82dbd77 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:34:06 +0200
Subject: [PATCH 14/24] Update README.md
---
README.md | 17 -----------------
1 file changed, 17 deletions(-)
diff --git a/README.md b/README.md
index 2eb08ab..952fdef 100644
--- a/README.md
+++ b/README.md
@@ -9,23 +9,6 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
-
- $ python run_downloader.py -h
- usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
-
- Download the tiktoks for the requested hashtags
-
- optional arguments:
- -h, --help show this help message and exit
- -t [T [T ...]] List of hashtags
- -f F File name with the list of hashtags
- -p Download posts
- -v Download videos
-
-
-
-
-
### Options for running run_downloader.py
python3 run_downloader.py -h
From dbf6eb595e608733e41a27a4d3ba4defa034c14f Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:36:38 +0200
Subject: [PATCH 15/24] Update README.md
---
README.md | 4 ++++
1 file changed, 4 insertions(+)
diff --git a/README.md b/README.md
index 952fdef..1496413 100644
--- a/README.md
+++ b/README.md
@@ -34,6 +34,10 @@ $ python run_downloader.py -h
+`pip install numpy`
+
+
+
### Post download
Run the run_downloader.py with the following option:
From ccd185aa87910420bf31f735010c5350baae33c7 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:37:49 +0200
Subject: [PATCH 16/24] Update README.md
---
README.md | 8 +++++++-
1 file changed, 7 insertions(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 1496413..13f6b06 100644
--- a/README.md
+++ b/README.md
@@ -34,7 +34,13 @@ $ python run_downloader.py -h
-`pip install numpy`
+```
+pip install numpy
+
+sjdfhshfs
+sjsdhfsjhfs
+skjdfhskjhfs
+```
From 3e0dd154d898f4bd888ad19d91cdff9c2c07e22e Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:38:27 +0200
Subject: [PATCH 17/24] Update README.md
---
README.md | 10 ----------
1 file changed, 10 deletions(-)
diff --git a/README.md b/README.md
index 13f6b06..952fdef 100644
--- a/README.md
+++ b/README.md
@@ -34,16 +34,6 @@ $ python run_downloader.py -h
-```
-pip install numpy
-
-sjdfhshfs
-sjsdhfsjhfs
-skjdfhskjhfs
-```
-
-
-
### Post download
Run the run_downloader.py with the following option:
From 137be843054266c168fbc7ac49545c7d888afa22 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:39:49 +0200
Subject: [PATCH 18/24] Update README.md
---
README.md | 18 +++++++++++++++++-
1 file changed, 17 insertions(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 952fdef..e24c844 100644
--- a/README.md
+++ b/README.md
@@ -25,7 +25,23 @@ $ python run_downloader.py -h
tree ../data
-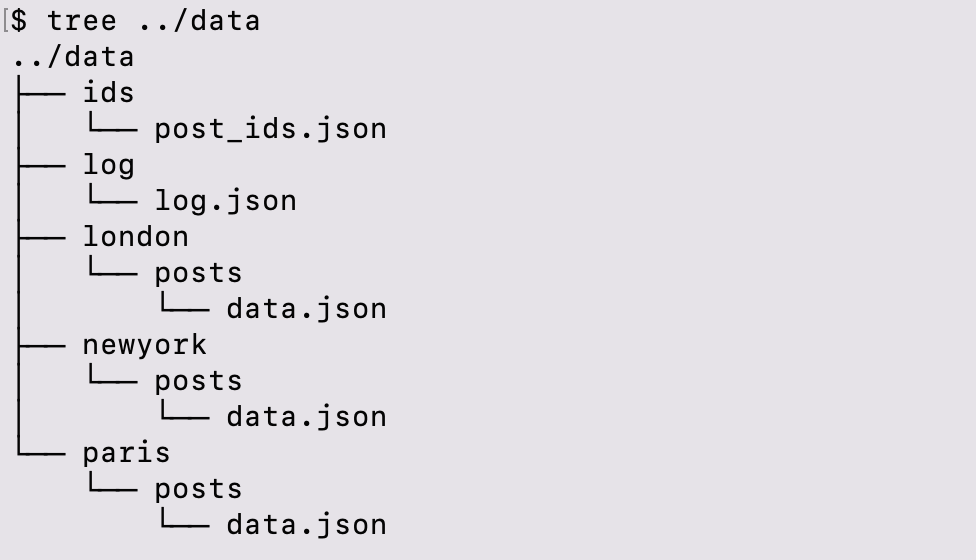 +```
+$ tree ../data
+../data
+├── ids
+│ └── post_ids.json
+├── log
+│ └── log.json
+├── london
+│ └── posts
+│ └── data.json
+├── newyork
+│ └── posts
+│ └── data.json
+└── paris
+ └── posts
+ └── data.json
+```
+```
+$ tree ../data
+../data
+├── ids
+│ └── post_ids.json
+├── log
+│ └── log.json
+├── london
+│ └── posts
+│ └── data.json
+├── newyork
+│ └── posts
+│ └── data.json
+└── paris
+ └── posts
+ └── data.json
+```
data folder contains all the downloaded data as shown in the picture above.
1. the log folder contains log.json which records the total number of downloaded posts and videos for the hashtags against the time stamp of when the script is run.
From 24e5828ec9643441d6d063fac19570a2ba8dbce1 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:40:10 +0200
Subject: [PATCH 19/24] Update README.md
---
README.md | 2 --
1 file changed, 2 deletions(-)
diff --git a/README.md b/README.md
index e24c844..76577c3 100644
--- a/README.md
+++ b/README.md
@@ -23,8 +23,6 @@ $ python run_downloader.py -h
### Data organization
- tree ../data
-
```
$ tree ../data
../data
From 304293046a6cec82d1623567a150a53b4af68634 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:40:47 +0200
Subject: [PATCH 20/24] Update README.md
---
README.md | 16 ++++++++++++++--
1 file changed, 14 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index 76577c3..811829a 100644
--- a/README.md
+++ b/README.md
@@ -11,10 +11,22 @@ The tool helps to download posts and videos from tiktok for a given set of hasht
### Options for running run_downloader.py
- python3 run_downloader.py -h
+```
+$ python run_downloader.py -h
+usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
+
+Download the tiktoks for the requested hashtags
+
+optional arguments:
+-h, --help show this help message and exit
+-t [T [T ...]] List of hashtags
+-f F File name with the list of hashtags
+-p Download posts
+-v Download videos
+```
+
-
$ python run_downloader.py -h
From 0b15617b5cf7922c169e4a9f8d60243c0ba326ba Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:41:13 +0200
Subject: [PATCH 21/24] Update README.md
---
README.md | 6 ------
1 file changed, 6 deletions(-)
diff --git a/README.md b/README.md
index 811829a..5b00fc4 100644
--- a/README.md
+++ b/README.md
@@ -27,12 +27,6 @@ optional arguments:
-
-$ python run_downloader.py -h
-
-
-
-
### Data organization
```
From fa2f113b4243afe2039e0ab263d743269955f656 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:41:42 +0200
Subject: [PATCH 22/24] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 5b00fc4..e40c353 100644
--- a/README.md
+++ b/README.md
@@ -57,7 +57,7 @@ $ tree ../data
### Post download
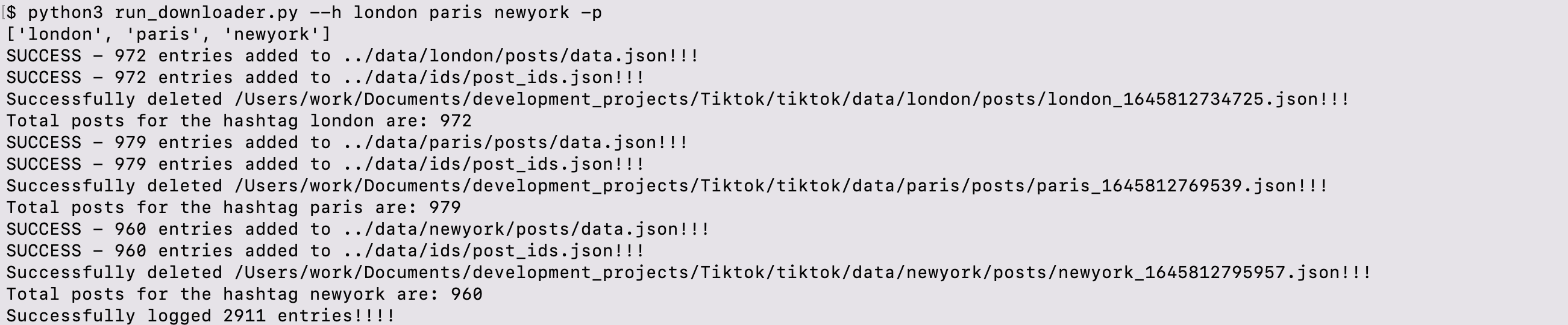
Run the run_downloader.py with the following option:
- python3 run_downloader.py --h london paris newyork -p
+ python3 run_downloader.py --h london paris newyork -p
 From ed15e3b6d75f8b819caa5d881f847a4cc62b8011 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:42:27 +0200
Subject: [PATCH 23/24] Update README.md
---
README.md | 21 +++++++++++++++++----
1 file changed, 17 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index e40c353..46a8446 100644
--- a/README.md
+++ b/README.md
@@ -56,10 +56,23 @@ $ tree ../data
### Post download
Run the run_downloader.py with the following option:
-
-
From ed15e3b6d75f8b819caa5d881f847a4cc62b8011 Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:42:27 +0200
Subject: [PATCH 23/24] Update README.md
---
README.md | 21 +++++++++++++++++----
1 file changed, 17 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index e40c353..46a8446 100644
--- a/README.md
+++ b/README.md
@@ -56,10 +56,23 @@ $ tree ../data
### Post download
Run the run_downloader.py with the following option:
-
- python3 run_downloader.py --h london paris newyork -p
-
-
+```
+$ python3 run_downloader.py -t london paris newyork -p
+['london', 'paris', 'newyork']
+SUCCESS - 962 entries added to ../data/london/posts/data.json!!!
+SUCCESS - 962 entries added to ../data/ids/post_ids.json!!!
+Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/london/posts/london_1651533070680.json!!!
+Total posts for the hashtag london are: 962
+SUCCESS - 961 entries added to ../data/paris/posts/data.json!!!
+SUCCESS - 961 entries added to ../data/ids/post_ids.json!!!
+Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/paris/posts/paris_1651533102789.json!!!
+Total posts for the hashtag paris are: 961
+SUCCESS - 941 entries added to ../data/newyork/posts/data.json!!!
+SUCCESS - 941 entries added to ../data/ids/post_ids.json!!!
+Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/newyork/posts/newyork_1651533125549.json!!!
+Total posts for the hashtag newyork are: 941
+Successfully logged 2864 entries!!!!
+```
1. The --h option allows to type in hashtag list in the commandline.
2. -p option specifies the download posts option.
From 234b763f49bfcc719c09acafdebf9eaf9d9783df Mon Sep 17 00:00:00 2001
From: johannawild <72805812+johannawild@users.noreply.github.com>
Date: Wed, 4 May 2022 00:44:04 +0200
Subject: [PATCH 24/24] Update README.md
---
README.md | 25 ++++++++++++++++++++++++-
1 file changed, 24 insertions(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 46a8446..cee876b 100644
--- a/README.md
+++ b/README.md
@@ -97,7 +97,30 @@ Assume we want to plot the graph of top 20 occurring hashtags in the downloaded
The figure above shows the top 20 occurring hashtags among all the posts downloaded for the hashtag london. Clearly, the highest occurrence will be of the hashtag london as the file data/london/posts/data.json contain all the posts with hashtag london.
2. Printing the result in the shell: python3 hashtag_frequencies.py -d ../data/london/posts/data.json 20 -v
-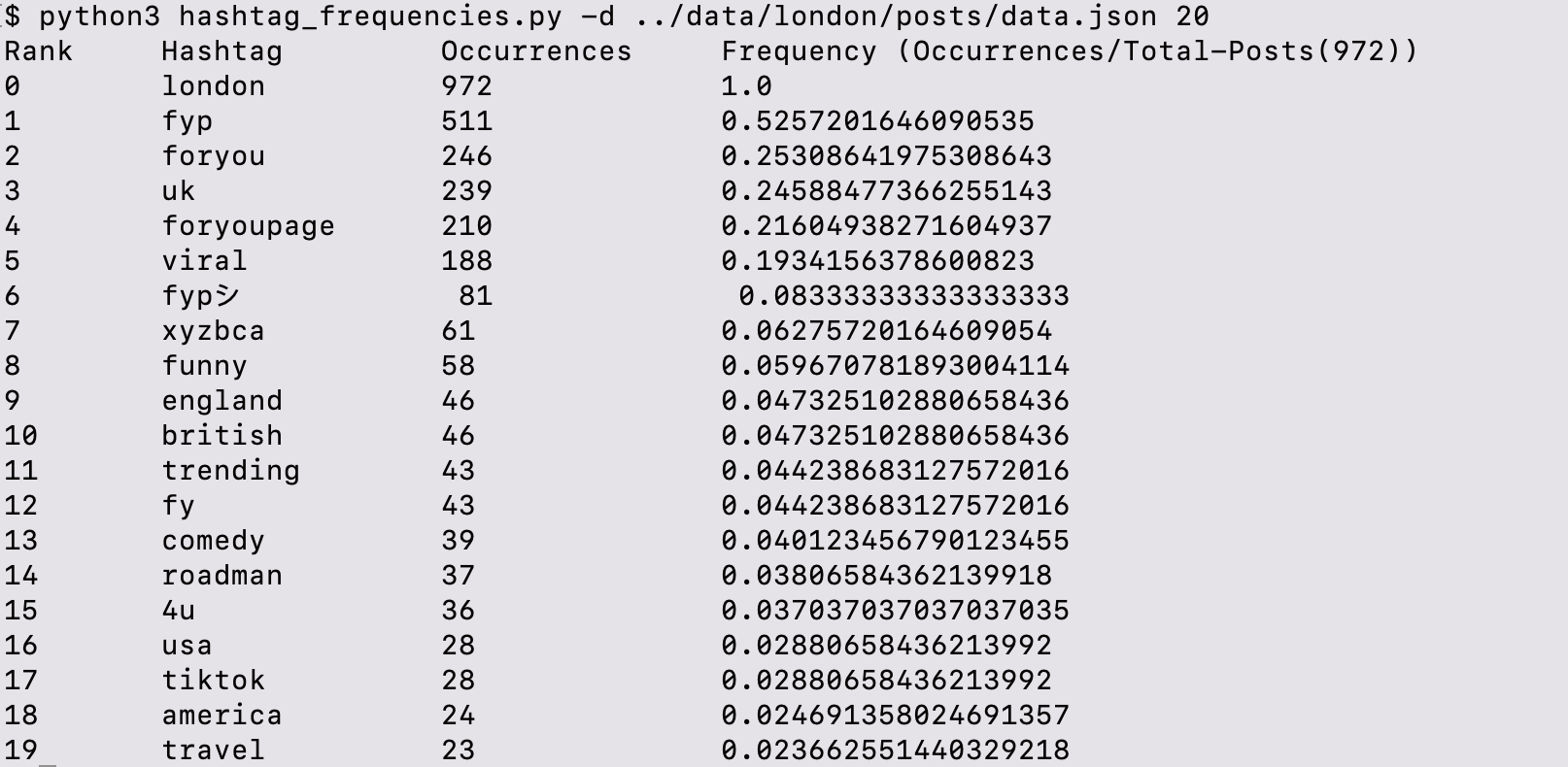 +
+```
+Rank Hashtag Occurrences Frequency (Occurrences/Total-Posts(total_posts))
+0 london 962 1.0
+1 fyp 493 0.5124740124740125
+2 uk 238 0.24740124740124741
+3 foryou 223 0.23180873180873182
+4 foryoupage 186 0.19334719334719336
+5 viral 177 0.183991683991684
+6 fypシ 85 0.08835758835758836
+7 funny 55 0.057172557172557176
+8 xyzbca 52 0.05405405405405406
+9 england 45 0.04677754677754678
+10 british 44 0.04573804573804574
+11 trending 39 0.04054054054054054
+12 fy 33 0.034303534303534305
+13 comedy 32 0.033264033264033266
+14 roadman 28 0.029106029106029108
+15 4u 27 0.028066528066528068
+16 usa 26 0.02702702702702703
+17 tiktok 26 0.02702702702702703
+18 travel 21 0.02182952182952183
+19 america 20 0.02079002079002079
+```
The same result of 1 is printed in the shell. The last column shows the ratio of the occurrence to the total posts.
+
+```
+Rank Hashtag Occurrences Frequency (Occurrences/Total-Posts(total_posts))
+0 london 962 1.0
+1 fyp 493 0.5124740124740125
+2 uk 238 0.24740124740124741
+3 foryou 223 0.23180873180873182
+4 foryoupage 186 0.19334719334719336
+5 viral 177 0.183991683991684
+6 fypシ 85 0.08835758835758836
+7 funny 55 0.057172557172557176
+8 xyzbca 52 0.05405405405405406
+9 england 45 0.04677754677754678
+10 british 44 0.04573804573804574
+11 trending 39 0.04054054054054054
+12 fy 33 0.034303534303534305
+13 comedy 32 0.033264033264033266
+14 roadman 28 0.029106029106029108
+15 4u 27 0.028066528066528068
+16 usa 26 0.02702702702702703
+17 tiktok 26 0.02702702702702703
+18 travel 21 0.02182952182952183
+19 america 20 0.02079002079002079
+```
The same result of 1 is printed in the shell. The last column shows the ratio of the occurrence to the total posts.