mirror of
https://github.com/bellingcat/tiktok-hashtag-analysis.git
synced 2026-06-11 12:58:30 +03:00
Merge pull request #4 from bellingcat/more_tristan_edits
More tristan edits
This commit is contained in:
58
README.md
58
README.md
@@ -2,14 +2,19 @@
|
||||
The tool helps to download posts and videos from TikTok for a given set of hashtags. It uses the [tiktok-scraper](https://github.com/drawrowfly/tiktok-scraper) Node package to download the posts and videos.
|
||||
|
||||
## Pre-requisites
|
||||
1. Make sure you have Python 3.6 or a later version installed.
|
||||
1. Make sure you have Python 3.6 or a later version installed
|
||||
2. Download and install TikTok scraper: https://github.com/drawrowfly/tiktok-scraper
|
||||
3. (Optional) create and activate a virtual environment for this tool, for example by executing the following command, which creates the `env` virtual environment:
|
||||
3. (Optional) create and activate a virtual environment for this tool, for example by executing the following command, which creates the `.env` virtual environment in the tool's root directory:
|
||||
|
||||
`python3 -m venv env`
|
||||
4. Start your virtual environment
|
||||
`source ./env/bin/activate`
|
||||
5. Run `pip install -r requirements.txt`
|
||||
`python3 -m venv .env`
|
||||
|
||||
4. Start your virtual environment
|
||||
- On Unix-like operating systems (macOS, Linux), this can be done using the command `source .env/bin/activate`
|
||||
- On Windows, this can be done using the command `.env\Scripts\activate.bat`
|
||||
|
||||
5. Install the Python package dependencies for this tool by executing the command:
|
||||
|
||||
`pip install -r requirements.txt`
|
||||
|
||||
You should now be ready to start using the tool.
|
||||
|
||||
@@ -36,8 +41,6 @@ $ tree ../data
|
||||
../data
|
||||
├── ids
|
||||
│ └── post_ids.json
|
||||
├── log
|
||||
│ └── log.json
|
||||
├── london
|
||||
│ └── posts
|
||||
│ └── data.json
|
||||
@@ -51,7 +54,6 @@ $ tree ../data
|
||||
|
||||
|
||||
The `data` folder contains all the downloaded data as shown in the tree diagram above.
|
||||
- (Depricated: logging info is now found in logfile.py in the project folder.) The `log` folder contains the `log.json` file, which records the total number of downloaded posts and videos for the hashtags against the timestamp of when the script was run.
|
||||
- The `ids` folder contains two files `post_ids.json` and `video_ids.json` that record the ids of the downloaded posts and videos for each hashtag.
|
||||
- Each hashtag has a folder with two subfolders `posts` and `videos` that store posts and videos respectively. The posts are stored in the `data.json` file in the `posts` folder, and videos are stored as the `.mp4` files in the `videos` folder.
|
||||
|
||||
@@ -65,32 +67,23 @@ Running the `run_downloader.py` script with the following options will scrape po
|
||||
and will produce an output similar to the following log:
|
||||
|
||||
$ python3 run_downloader.py -t london paris newyork -p
|
||||
['london', 'paris', 'newyork']
|
||||
SUCCESS - 962 entries added to ../data/london/posts/data.json!!!
|
||||
SUCCESS - 962 entries added to ../data/ids/post_ids.json!!!
|
||||
Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/london/posts/london_1651533070680.json!!!
|
||||
Total posts for the hashtag london are: 962
|
||||
SUCCESS - 961 entries added to ../data/paris/posts/data.json!!!
|
||||
SUCCESS - 961 entries added to ../data/ids/post_ids.json!!!
|
||||
Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/paris/posts/paris_1651533102789.json!!!
|
||||
Total posts for the hashtag paris are: 961
|
||||
SUCCESS - 941 entries added to ../data/newyork/posts/data.json!!!
|
||||
SUCCESS - 941 entries added to ../data/ids/post_ids.json!!!
|
||||
Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/newyork/posts/newyork_1651533125549.json!!!
|
||||
Total posts for the hashtag newyork are: 941
|
||||
Successfully logged 2864 entries!!!!
|
||||
Hashtags to scrape: ['london', 'paris', 'newyork']
|
||||
Scraped 963 posts containing the hashtag 'london'
|
||||
Scraped 961 posts containing the hashtag 'paris'
|
||||
Scraped 940 posts containing the hashtag 'newyork'
|
||||
Successfully scraped 2864 total entries
|
||||
|
||||
- The `-t` flag allows a space-separated list of hashtags to be specified as a command line argument
|
||||
- The `-p` flag specifies that posts, not videos, will be downloaded
|
||||
|
||||
### Video downloading
|
||||
Running the `run_downloader.py` script with the following options will scrape trending videos containing the hashtags `#london`, `#paris`, or `#newyork`:
|
||||
Running the `run_downloader.py` script with the following options will scrape trending videos containing the hashtag `#london`:
|
||||
` python3 run_downloader.py -t london -v`
|
||||
|
||||
- The `-t` flag allows a space-separated list of hashtags to be specified as a command line argument
|
||||
- The `-v` flag specifies that videos, not posts, will be downloaded
|
||||
|
||||
Note that video downloading is a time and data rate consuming task, as a result we strongly recommend using one hashtag at a time when using the `-v` flag to avoid complications.
|
||||
Note that video downloading is a time and data rate consuming task, as a result we recommend using one hashtag at a time when using the `-v` flag to avoid complications.
|
||||
|
||||
## Analyzing results
|
||||
### Top n hashtag occurrences
|
||||
@@ -110,17 +103,18 @@ optional arguments:
|
||||
-d, --print List top n hashtags
|
||||
```
|
||||
|
||||
Assume we want to analyze the top 20 occurring hashtags in the downloaded posts of the `#london` hashtag.
|
||||
Assume we want to analyze the 20 most frequently occurring hashtags in the downloaded posts of the `#london` hashtag.
|
||||
|
||||
- The results can be plotted and saved as a PNG file by executing the following command:
|
||||
|
||||
`python3 hashtag_frequencies.py -p ../data/london/posts/data.json 20`
|
||||
|
||||
which will produce a figure similar to that shown below:
|
||||
|
||||
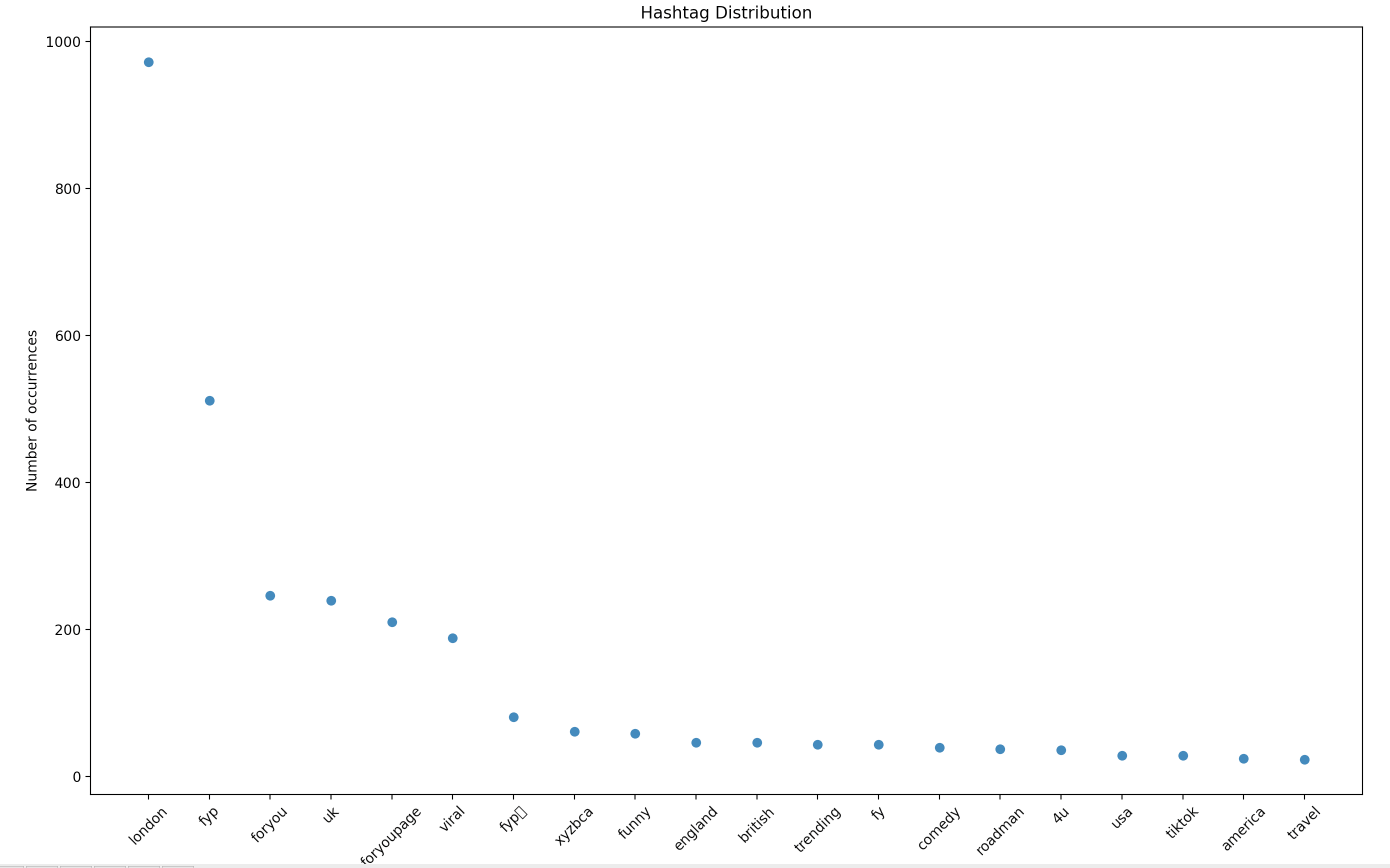
|
||||
|
||||
Clearly, the highest occurrence will be of the `#london` hashtag, as all posts in the file `data/london/posts/data.json` contain the hashtag `#london`.
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/18430739/166878928-d146b352-b68c-4ab4-bd2c-feb2f0140df9.png" height="500" alt="Top 20 most frequent common hashtags in posts containing the #london hashtag">
|
||||
</p>
|
||||
|
||||
In the above plot, the highest occurrence is the `#fyp` hashtag, which is tagged in more than half of all posts containing the `#london` hashtag.
|
||||
|
||||
- The results can be displayed in tabular form by executing the following command:
|
||||
|
||||
@@ -128,7 +122,7 @@ Assume we want to analyze the top 20 occurring hashtags in the downloaded posts
|
||||
|
||||
which will produce a terminal output similar to the following:
|
||||
```
|
||||
Rank Hashtag Occurrences Frequency (Occurrences/Total-Posts(total_posts))
|
||||
Rank Hashtag Occurrences Frequency
|
||||
0 london 962 1.0
|
||||
1 fyp 493 0.5124740124740125
|
||||
2 uk 238 0.24740124740124741
|
||||
@@ -151,4 +145,4 @@ Assume we want to analyze the top 20 occurring hashtags in the downloaded posts
|
||||
19 america 20 0.02079002079002079
|
||||
```
|
||||
|
||||
The `Frequency` column shows the ratio of the occurrence to the total number of downloaded posts.
|
||||
The `Frequency` column shows the ratio of the occurrence to the total number of downloaded posts.
|
||||
|
||||
32
logging.ini
32
logging.ini
@@ -1,32 +0,0 @@
|
||||
[loggers]
|
||||
keys=root
|
||||
|
||||
[handlers]
|
||||
keys=consoleHandler,fileHandler
|
||||
|
||||
[formatters]
|
||||
keys=consoleFormatter,fileFormatter
|
||||
|
||||
[logger_root]
|
||||
level=INFO
|
||||
handlers=consoleHandler,fileHandler
|
||||
|
||||
[handler_consoleHandler]
|
||||
class=StreamHandler
|
||||
level=DEBUG
|
||||
formatter=consoleFormatter
|
||||
args=(sys.stdout,)
|
||||
|
||||
[handler_fileHandler]
|
||||
class=FileHandler
|
||||
level=WARNING
|
||||
formatter=fileFormatter
|
||||
args=("../logfile.log",)
|
||||
|
||||
[formatter_fileFormatter]
|
||||
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
|
||||
datefmt=
|
||||
|
||||
[formatter_consoleFormatter]
|
||||
format=%(levelname)s - %(message)s
|
||||
datefmt=
|
||||
@@ -1 +1,2 @@
|
||||
matplotlib==3.5.2
|
||||
matplotlib
|
||||
seaborn
|
||||
@@ -1,16 +1,12 @@
|
||||
from collections import namedtuple
|
||||
import warnings
|
||||
import logging
|
||||
|
||||
import file_methods
|
||||
|
||||
# setting up the logging
|
||||
import logging
|
||||
from logging.config import fileConfig
|
||||
|
||||
fileConfig('../logging.ini')
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
|
||||
|
||||
"""
|
||||
The file contains several functions that perform data processing related tasks.
|
||||
"""
|
||||
@@ -62,8 +58,7 @@ def extract_posts(settings, file_name, tag):
|
||||
ids.append(post["id"])
|
||||
|
||||
if not ids:
|
||||
logger.warn(f"WARNING: no posts were found for {tag} in the file - {file_name}")
|
||||
return
|
||||
warnings.warn(f"No posts were found for {tag} in the file - {file_name}")
|
||||
|
||||
status = file_methods.check_existence(settings["post_ids"], "file")
|
||||
if not status:
|
||||
@@ -72,8 +67,7 @@ def extract_posts(settings, file_name, tag):
|
||||
else:
|
||||
new_ids = get_difference(tag, settings["post_ids"], ids)
|
||||
if not new_ids:
|
||||
logger.warn(f"WARNING: No new posts were found in the downloaded file - {file_name}")
|
||||
return
|
||||
warnings.warn(f"No new posts were found in the downloaded file - {file_name}")
|
||||
elif new_ids.filter_posts:
|
||||
new_posts = [post for post in posts if post['id'] in new_ids.ids]
|
||||
new_data = (new_ids.ids, new_posts)
|
||||
@@ -94,8 +88,8 @@ def extract_videos(settings, tag, download_list):
|
||||
else:
|
||||
new_videos = get_difference(tag, settings["video_ids"], download_list)
|
||||
if not new_videos:
|
||||
logger.warn(f"WARNING: No new videos were found for the {tag} in the downloaded folder.")
|
||||
return
|
||||
warnings.warn(f"No new videos were found for the {tag} in the downloaded folder.")
|
||||
return None
|
||||
else:
|
||||
return new_videos.ids
|
||||
|
||||
@@ -104,15 +98,12 @@ def update_posts(file_path, file_type, new_data, tag=None):
|
||||
"""
|
||||
Updates the list of post ids (in the file ids/post_ids.json) with the ids of the new posts.
|
||||
"""
|
||||
try:
|
||||
status = file_methods.check_existence(file_path, file_type)
|
||||
if not tag:
|
||||
file_methods.post_writer(file_path, new_data, status)
|
||||
else:
|
||||
log = file_methods.id_writer(file_path, new_data, tag, status)
|
||||
return log
|
||||
except:
|
||||
raise
|
||||
status = file_methods.check_existence(file_path, file_type)
|
||||
if not tag:
|
||||
file_methods.post_writer(file_path, new_data, status)
|
||||
else:
|
||||
scraped_data = file_methods.id_writer(file_path, new_data, tag, status)
|
||||
return scraped_data
|
||||
|
||||
|
||||
def update_videos(settings, new_data, tag):
|
||||
@@ -147,8 +138,6 @@ def print_total(file_path, tag, data_type):
|
||||
"""
|
||||
total = get_total_posts(file_path, tag)
|
||||
if (total.total == total.unique):
|
||||
logger.info(f"Total {data_type} for the hashtag {tag} are: {total.total}")
|
||||
return
|
||||
logger.info(f"Scraped {total.total} {data_type} containing the hashtag '{tag}'")
|
||||
else:
|
||||
logger.warn(f"WARNING: out of total {data_type} for the hashtag {tag} {total.total}, only {total.unique} are unique. Something is going wrong...")
|
||||
return
|
||||
warnings.warn(f"Out of total {data_type} for the hashtag {tag} {total.total}, only {total.unique} are unique. Something is going wrong...")
|
||||
|
||||
@@ -1,18 +1,17 @@
|
||||
import os, json, subprocess
|
||||
import os
|
||||
import json
|
||||
import subprocess
|
||||
from datetime import datetime
|
||||
import global_data
|
||||
import shutil
|
||||
import warnings
|
||||
|
||||
|
||||
# setting up the logging
|
||||
import logging
|
||||
from logging.config import fileConfig
|
||||
|
||||
fileConfig('../logging.ini')
|
||||
logging.basicConfig(
|
||||
level = logging.INFO,
|
||||
format = '%(message)s')
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
|
||||
"""
|
||||
The file contains the functions that operate on files, such as writing or reading from files etc.
|
||||
"""
|
||||
@@ -27,8 +26,7 @@ def create_file(name, file_type):
|
||||
elif (file_type == "file"):
|
||||
with open(name, "w"): pass
|
||||
else:
|
||||
logger.exception(f"{file_type} has to be a 'dir' or a 'file'!!!")
|
||||
return
|
||||
raise ValueError(f"{file_type} has to be either 'dir' or 'file'")
|
||||
|
||||
|
||||
def check_existence(file_path, file_type):
|
||||
@@ -40,7 +38,7 @@ def check_existence(file_path, file_type):
|
||||
elif (file_type == "dir"):
|
||||
return os.path.isdir(file_path)
|
||||
else:
|
||||
logger.exception(f"{file_type} has to be a 'dir' or a 'file'!!!")
|
||||
raise ValueError(f"{file_type} has to be either 'dir' or 'file'")
|
||||
|
||||
|
||||
def check_file(file_path, file_type):
|
||||
@@ -51,8 +49,6 @@ def check_file(file_path, file_type):
|
||||
if not status:
|
||||
create_file(file_path, file_type)
|
||||
|
||||
return
|
||||
|
||||
|
||||
def download_posts(settings, tag):
|
||||
"""
|
||||
@@ -62,18 +58,15 @@ def download_posts(settings, tag):
|
||||
"""
|
||||
path = os.path.join(settings["data"], tag, settings["posts"])
|
||||
os.chdir(path)
|
||||
try:
|
||||
tiktok_command = f"tiktok-scraper hashtag {tag} -t 'json'"
|
||||
result = subprocess.check_output(tiktok_command, shell=True)
|
||||
new_file = result.decode('utf-8').split()[-1]
|
||||
if ("json" in new_file):
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return new_file
|
||||
else:
|
||||
logger.warn(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return
|
||||
except: raise
|
||||
tiktok_command = f"tiktok-scraper hashtag {tag} -t 'json'"
|
||||
output = subprocess.check_output(tiktok_command, shell=True, encoding = 'utf-8')
|
||||
new_file = output.split()[-1]
|
||||
if ("json" in new_file):
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return new_file
|
||||
else:
|
||||
warnings.warn(f"Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file.\n\ntiktok-scraper returned {output}")
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
|
||||
|
||||
|
||||
@@ -85,27 +78,22 @@ def download_videos(settings, tag):
|
||||
"""
|
||||
path = os.path.join(settings["data"], tag, settings["videos"])
|
||||
os.chdir(path)
|
||||
try:
|
||||
# tiktok_command = f"tiktok-scraper hashtag {tag} -n {settings['number_of_videos']} -d"
|
||||
tiktok_command = f"tiktok-scraper hashtag {tag} -d"
|
||||
result = subprocess.check_output(tiktok_command, shell=True)
|
||||
downloaded_list_tmp = os.listdir(f"./#{tag}")
|
||||
if downloaded_list_tmp:
|
||||
downloaded_list = []
|
||||
for file in downloaded_list_tmp:
|
||||
file = file.split('.')[0]
|
||||
downloaded_list.append(file)
|
||||
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return downloaded_list
|
||||
else:
|
||||
print(f"WARNING: No video files were downloaded for the hashtag {tag}.")
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
shutil.rmtree(settings['videos_delete'])
|
||||
#subprocess.call(f"rm -rf {settings['videos_delete']}", shell=True)
|
||||
tiktok_command = f"tiktok-scraper hashtag {tag} -d"
|
||||
result = subprocess.check_output(tiktok_command, shell=True)
|
||||
downloaded_list_tmp = os.listdir(f"./#{tag}")
|
||||
if downloaded_list_tmp:
|
||||
downloaded_list = []
|
||||
for file in downloaded_list_tmp:
|
||||
file = file.split('.')[0]
|
||||
downloaded_list.append(file)
|
||||
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
return downloaded_list
|
||||
else:
|
||||
warnings.warn(f"No video files were downloaded for the hashtag {tag}.")
|
||||
os.chdir("../../../tiktok_downloader")
|
||||
shutil.rmtree(settings['videos_delete'])
|
||||
|
||||
except: raise
|
||||
|
||||
|
||||
def get_data(file_path):
|
||||
"""
|
||||
@@ -122,7 +110,6 @@ def dump_data(file_path, data):
|
||||
"""
|
||||
with open(file_path, "w", encoding = "utf-8") as f:
|
||||
json.dump(data, f)
|
||||
return
|
||||
|
||||
def log_writer(log_data):
|
||||
"""
|
||||
@@ -131,78 +118,67 @@ def log_writer(log_data):
|
||||
Writes the dictionary to the log file (logs/log.json).
|
||||
"""
|
||||
total = 0
|
||||
try:
|
||||
log_dict = {}
|
||||
for ele in log_data:
|
||||
if ele[0] in log_dict:
|
||||
if ele[1][0] in log_dict[ele[0]]:
|
||||
log_dict[ele[0]][ele[1][0]] += ele[1][1]
|
||||
else:
|
||||
log_dict[ele[0]][ele[1][0]] = ele[1][1]
|
||||
total += ele[1][1]
|
||||
scraped_summary_dict = {}
|
||||
for hashtag, (data_type, count) in log_data:
|
||||
if hashtag in scraped_summary_dict:
|
||||
if data_type in scraped_summary_dict[hashtag]:
|
||||
scraped_summary_dict[hashtag][data_type] += count
|
||||
else:
|
||||
log_dict[ele[0]] = { ele[1][0] : ele[1][1] }
|
||||
total += ele[1][1]
|
||||
scraped_summary_dict[hashtag][data_type] = count
|
||||
total += count
|
||||
else:
|
||||
scraped_summary_dict[hashtag] = {data_type : count}
|
||||
total += count
|
||||
|
||||
now = datetime.now()
|
||||
now_str = now.strftime("%d-%m-%Y %H:%M:%S")
|
||||
data = { now_str : log_dict }
|
||||
now = datetime.now()
|
||||
now_str = now.strftime("%d-%m-%Y %H:%M:%S")
|
||||
data = { now_str : scraped_summary_dict }
|
||||
|
||||
logger.warn(data)
|
||||
logger.info(f"Successfully logged {total} entries!!!!")
|
||||
return
|
||||
except:
|
||||
logger.exception()
|
||||
logger.debug(f"Logged post data: {data}")
|
||||
logger.info(f"Successfully scraped {total} total entries")
|
||||
|
||||
|
||||
def id_writer(file_path, new_data, tag, status):
|
||||
"""
|
||||
Writes the list of new ids to the post_ids or video_ds files.
|
||||
Writes the list of new ids to the post_ids or video_ids files.
|
||||
"""
|
||||
try:
|
||||
total = len(new_data)
|
||||
if status:
|
||||
try:
|
||||
data = get_data(file_path)
|
||||
if tag in data:
|
||||
data[tag] += new_data
|
||||
else:
|
||||
data[tag]= new_data
|
||||
dump_data(file_path, data)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = { tag : new_data }
|
||||
dump_data(file_path, data)
|
||||
else:
|
||||
total = len(new_data)
|
||||
if status:
|
||||
try:
|
||||
data = get_data(file_path)
|
||||
if tag in data:
|
||||
data[tag] += new_data
|
||||
else:
|
||||
data[tag]= new_data
|
||||
dump_data(file_path, data)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = { tag : new_data }
|
||||
dump_data(file_path, data)
|
||||
logger.info(f"SUCCESS - {total} entries added to {file_path}!!!")
|
||||
log_data = (tag, total)
|
||||
return log_data
|
||||
except:
|
||||
logger.exception()
|
||||
else:
|
||||
data = { tag : new_data }
|
||||
dump_data(file_path, data)
|
||||
logger.debug(f"SUCCESS - {total} entries added to {file_path}")
|
||||
number_scraped = (tag, total)
|
||||
return number_scraped
|
||||
|
||||
|
||||
def post_writer(file_path, new_data, status):
|
||||
"""
|
||||
Writes the new posts in the post file of the given hashtag (/data/{hashtag}/posts/data.json)
|
||||
"""
|
||||
try:
|
||||
total = len(new_data)
|
||||
if status:
|
||||
try:
|
||||
data = get_data(file_path)
|
||||
data += new_data
|
||||
dump_data(file_path, data)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = new_data
|
||||
dump_data(file_path, data)
|
||||
else:
|
||||
total = len(new_data)
|
||||
if status:
|
||||
try:
|
||||
data = get_data(file_path)
|
||||
data += new_data
|
||||
dump_data(file_path, data)
|
||||
except json.decoder.JSONDecodeError:
|
||||
data = new_data
|
||||
dump_data(file_path, data)
|
||||
logger.info(f"SUCCESS - {total} entries added to {file_path}!!!")
|
||||
return
|
||||
except:
|
||||
logger.exception()
|
||||
else:
|
||||
data = new_data
|
||||
dump_data(file_path, data)
|
||||
logger.debug(f"SUCCESS - {total} entries added to {file_path}")
|
||||
|
||||
|
||||
def delete_file(file_path, file_type):
|
||||
@@ -210,17 +186,15 @@ def delete_file(file_path, file_type):
|
||||
Deletes the directory or the file.
|
||||
"""
|
||||
if not check_existence(file_path, file_type):
|
||||
logger.exception(f"ERROR: Attempt to delete failed. {file_path} does not exist!!!")
|
||||
raise OSError(f"Attempt to delete file failed: {file_path} does not exist")
|
||||
elif (file_type == "file"):
|
||||
os.remove(file_path)
|
||||
logger.info(f"Successfully deleted {file_path}!!!")
|
||||
return
|
||||
logger.debug(f"Successfully deleted {file_path}")
|
||||
elif (file_type == "dir"):
|
||||
os.rmdir(file_path)
|
||||
logger.info(f"Successfully deleted {file_path}!!!")
|
||||
return
|
||||
logger.debug(f"Successfully deleted {file_path}")
|
||||
else:
|
||||
logger.exception(f"OSError: {file_type} needs to be either 'file' or 'dir' !!!")
|
||||
raise OSError("{file_type} needs to be either 'file' or 'dir'")
|
||||
|
||||
|
||||
def clean_video_files(settings, tag, new_data=None):
|
||||
@@ -228,13 +202,10 @@ def clean_video_files(settings, tag, new_data=None):
|
||||
Moves the new videos from the tiktok-scraper video folder to /data/{hashtag}/videos/
|
||||
Deletes the residual tiktok-scraper video folder.
|
||||
"""
|
||||
try:
|
||||
if new_data:
|
||||
for file in new_data:
|
||||
settings["videos_from"] = settings['data'] + f"/{tag}/videos/#{tag}/{file}.mp4"
|
||||
shutil.move(settings['videos_from'], settings['videos_to'])
|
||||
|
||||
shutil.rmtree(settings['videos_delete'])
|
||||
logger.info(f"Successfully deleted the folder {settings['videos_delete']} folder of videos.")
|
||||
except:
|
||||
raise
|
||||
if new_data:
|
||||
for file in new_data:
|
||||
settings["videos_from"] = settings['data'] + f"/{tag}/videos/#{tag}/{file}.mp4"
|
||||
shutil.move(settings['videos_from'], settings['videos_to'])
|
||||
|
||||
shutil.rmtree(settings['videos_delete'])
|
||||
logger.debug(f"Successfully deleted the folder {settings['videos_delete']} folder of videos.")
|
||||
|
||||
@@ -1,22 +1,27 @@
|
||||
import os, sys
|
||||
import os
|
||||
import json
|
||||
import argparse
|
||||
import matplotlib.pyplot as plt
|
||||
from datetime import datetime
|
||||
from file_methods import check_file
|
||||
from global_data import IMAGES
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore", message="Glyph (.*) missing from current font")
|
||||
import logging
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import matplotlib.ticker as mtick
|
||||
import seaborn as sns
|
||||
sns.set_theme(style="darkgrid")
|
||||
|
||||
from file_methods import check_file, check_existence
|
||||
from global_data import IMAGES
|
||||
|
||||
"""
|
||||
Plots the frequency of hashtags appearing in the set of given posts.
|
||||
"""
|
||||
|
||||
|
||||
|
||||
def get_hashtags(obj):
|
||||
if not obj:
|
||||
print(f'ERROR: Empty item, no hashtags to be extracted.')
|
||||
return
|
||||
raise ValueError(f'Empty item, no hashtags to be extracted.')
|
||||
else:
|
||||
hashtags = {}
|
||||
tags = [ [tag['name'] for tag in ele['hashtags']] for ele in obj ]
|
||||
@@ -50,15 +55,21 @@ def get_occurrences(filename, n=1 , sort=True):
|
||||
|
||||
|
||||
def plot(n, occs, img_folder):
|
||||
plt.scatter(occs["top_n"][0], occs["top_n"][1])
|
||||
plt.tight_layout()
|
||||
plt.xticks(rotation=45)
|
||||
plt.title(f'Hashtag Distribution')
|
||||
plt.xlabel(f'Top {n} hashtags from {occs["total"]} posts.')
|
||||
plt.ylabel(f'Number of occurrences')
|
||||
y_pos = list(reversed(range(n - 1)))
|
||||
max_count = occs["top_n"][1][0]
|
||||
freqs = [count/max_count * 100 for count in occs["top_n"][1][1:]]
|
||||
labels = occs["top_n"][0][1:]
|
||||
|
||||
fig, ax = plt.subplots(figsize = (5, 6.66))
|
||||
ax.barh(y_pos, freqs)
|
||||
ax.set_yticks(y_pos)
|
||||
ax.set_yticklabels(labels)
|
||||
ax.grid(axis = 'y')
|
||||
ax.set_xlabel('Percent of posts with common hashtag')
|
||||
ax.set_ylim(min(y_pos)-1, max(y_pos)+1)
|
||||
ax.set_title(f'Common hashtags for #{occs["top_n"][0][0]} posts')
|
||||
ax.xaxis.set_major_formatter(mtick.PercentFormatter(decimals = 0))
|
||||
save_plot(img_folder)
|
||||
plt.show(block=None)
|
||||
return
|
||||
|
||||
|
||||
def print_occurrences(occs):
|
||||
@@ -67,26 +78,22 @@ def print_occurrences(occs):
|
||||
"""
|
||||
row_number = 0
|
||||
total_posts = occs["total"]
|
||||
print ("{:<8} {:<15} {:<15} {:<15}".format("Rank", 'Hashtag','Occurrences',f'Frequency (Occurrences/Total-Posts(total_posts))'))
|
||||
print ("{:<8} {:<15} {:<15} {:<15}".format("Rank", 'Hashtag','Occurrences','Frequency'))
|
||||
for key,value in zip(occs["top_n"][0], occs["top_n"][1]):
|
||||
ratio = value/total_posts
|
||||
print ("{:<8} {:<15} {:<15} {:<15}".format(row_number, key, value, ratio))
|
||||
row_number += 1
|
||||
return
|
||||
|
||||
|
||||
def save_plot(img_folder):
|
||||
"""
|
||||
Saves the plot to a png file in the folder /data/imgs/
|
||||
"""
|
||||
try:
|
||||
now = datetime.now()
|
||||
current_time = now.strftime("%Y_%m_%d_%H_%M_%S")
|
||||
plt.savefig(f"{img_folder}/{current_time}.png")
|
||||
|
||||
return
|
||||
except: raise
|
||||
|
||||
now = datetime.now()
|
||||
current_time = now.strftime("%Y_%m_%d_%H_%M_%S")
|
||||
filename = f"{img_folder}/{current_time}.png"
|
||||
logging.info(f'Plot saved to file: {filename}')
|
||||
plt.savefig(filename, bbox_inches = 'tight', facecolor = 'white', dpi = 300)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
@@ -105,17 +112,14 @@ if __name__ == "__main__":
|
||||
parser.add_argument("-p", "--plot", help="Plot the occurrences", action="store_true")
|
||||
parser.add_argument("-d", "--print", help="List top n hashtags", action="store_true")
|
||||
args = parser.parse_args()
|
||||
if args.input_file and args.n:
|
||||
if args.n < 1:
|
||||
print(f"Please make sure the number of top occurrences is a positive integer.")
|
||||
sys.exit()
|
||||
|
||||
base = os.path.splitext(args.input_file)[0]
|
||||
path = f"./{base}_sorted_hashtags.csv"
|
||||
occs = get_occurrences(args.input_file, args.n)
|
||||
if args.plot:
|
||||
plot(args.n, occs, img_folder)
|
||||
else:
|
||||
print_occurrences(occs)
|
||||
if args.n < 1:
|
||||
raise ValueError(f"Specified argument `n` (the number of hashtags to analyze) must be greater than zero, not: {args.n}.")
|
||||
if not check_existence(args.input_file, 'file'):
|
||||
raise FileNotFoundError(f"Specified argument `input_file` ({args.input_file}) does not exist.")
|
||||
base = os.path.splitext(args.input_file)[0]
|
||||
path = f"./{base}_sorted_hashtags.csv"
|
||||
occs = get_occurrences(args.input_file, args.n)
|
||||
if args.plot:
|
||||
plot(args.n, occs, img_folder)
|
||||
else:
|
||||
print(f'ERROR: either {args.input_file} or {args.n} or both contains error.')
|
||||
print_occurrences(occs)
|
||||
|
||||
@@ -1,61 +1,20 @@
|
||||
import os
|
||||
import time
|
||||
import argparse
|
||||
import logging
|
||||
|
||||
import global_data
|
||||
import file_methods
|
||||
import data_methods
|
||||
|
||||
# setting up the logging
|
||||
import logging
|
||||
from logging.config import fileConfig
|
||||
|
||||
fileConfig('../logging.ini')
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
"""
|
||||
The run_downloader.py dowloads data using the tiktok-scraper (https://github.com/drawrowfly/tiktok-scraper).
|
||||
1. "-p" option is used by the user to download posts only
|
||||
2. "-v" option is use to download videos only
|
||||
3. "-p -v" is used to download posts and videos
|
||||
4. "-t" is used to specify a list of hashtags as arguments
|
||||
5. "-f" option is used to read the list of hashtags from the user specified file
|
||||
|
||||
Example:
|
||||
1. The command "python3 run_downloader.py -t london paris newyork -p" will download posts for hashtags london, paris and newyork.
|
||||
2. The command "python3 run_downloader.py -f hashtag_list -p -v" will download posts and videos for hashtags in the file hashtag_list.
|
||||
|
||||
|
||||
The downloaded data is stored in the the data folder. The data is folder is organized as follows:
|
||||
1. the log subfolder contains the log.json that records total downloads (posts and videos) for each hashtag with a timestamp of when the script was run.
|
||||
2. the ids subfolder contains post_ids.json and video_ids.json that keep the record of post and video ids that are currently in the data set. This helps to filter out only new posts every time tiktok-scraper is run and only those new posts (or videos) are then stored in the data folder.
|
||||
3. Each hashtag has a subfolder by its name containing two subfolders, one each for posts and videos.
|
||||
|
||||
|
||||
This scripts runs the function get_data in main which in turn triggers the following sequence:
|
||||
1. get_posts function is triggered if the user wants to download posts
|
||||
2. get_videos function is triggered if the user wants to download videos
|
||||
3. both functions above are sequentially triggered if the user wants to download both posts and videos.
|
||||
4. After the data is downloaded the log_writer is triggered to log the total number of posts and videos downloaded.
|
||||
|
||||
|
||||
------------Files--------------
|
||||
global_data - contains global constants relating to paths etc.
|
||||
data_methods - this file contains data processing methods
|
||||
file_methods - this file contains methods to write and update data in files
|
||||
hashtag_list - this file contains the list of hashtags that the user wants to download data for.
|
||||
"""
|
||||
|
||||
|
||||
|
||||
def get_hashtag_list(file_name):
|
||||
try:
|
||||
with open(file_name) as f:
|
||||
tags = list(filter(None, [line.strip() for line in f if not line.startswith("#")]))
|
||||
return tags
|
||||
except IOError:
|
||||
logger.exception(f"IOError")
|
||||
if not file_methods.check_existence(file_name, 'file'):
|
||||
raise OSError(f"{file_name} does not exist")
|
||||
with open(file_name) as f:
|
||||
tags = list(filter(None, [line.strip() for line in f if not line.startswith("#")]))
|
||||
return tags
|
||||
|
||||
|
||||
def create_parser():
|
||||
@@ -102,16 +61,16 @@ def get_posts(settings, tag):
|
||||
3. calls update_posts from data_methods.py to update the id-list with the ids of newly downloaded posts.
|
||||
"""
|
||||
file_path = file_methods.download_posts(settings, tag)
|
||||
log = ()
|
||||
number_scraped = ()
|
||||
if file_path:
|
||||
new_data = data_methods.extract_posts(settings, file_path, tag)
|
||||
if new_data:
|
||||
data_file = os.path.join(settings["data"], tag, settings["posts"], settings["data_file"])
|
||||
data_methods.update_posts(data_file, "file", new_data[1])
|
||||
log = data_methods.update_posts(settings["post_ids"], "file", new_data[0], tag)
|
||||
number_scraped = data_methods.update_posts(settings["post_ids"], "file", new_data[0], tag)
|
||||
file_methods.delete_file(file_path, "file")
|
||||
|
||||
return log
|
||||
return number_scraped
|
||||
|
||||
|
||||
|
||||
@@ -122,16 +81,16 @@ def get_videos(settings, tag):
|
||||
3. calls update_videos from data_methods.py to update the id-list with the ids of newly downloaded videos.
|
||||
4. the clean_video_files function deletes the residual video folder after the data processing
|
||||
"""
|
||||
log = ()
|
||||
number_scraped = ()
|
||||
download_list = file_methods.download_videos(settings, tag)
|
||||
if download_list:
|
||||
new_data = data_methods.extract_videos(settings, tag, download_list)
|
||||
if new_data:
|
||||
log = data_methods.update_videos(settings, new_data, tag)
|
||||
number_scraped = data_methods.update_videos(settings, new_data, tag)
|
||||
else:
|
||||
file_methods.clean_video_files(settings, tag)
|
||||
|
||||
return log
|
||||
return number_scraped
|
||||
|
||||
|
||||
|
||||
@@ -143,7 +102,7 @@ def get_data(hashtags, download_data_type):
|
||||
counter = 0
|
||||
total_hashtags = len(hashtags)
|
||||
total_hashtags_offset = total_hashtags - 1
|
||||
log_data = []
|
||||
scraped_summary_list = []
|
||||
|
||||
if download_data_type["posts"]:
|
||||
settings = set_download_settings(download_data_type)
|
||||
@@ -153,8 +112,8 @@ def get_data(hashtags, download_data_type):
|
||||
file_methods.check_file(os.path.join(settings["data"], tag, settings["posts"], settings["data_file"]), "file")
|
||||
res = get_posts(settings, tag)
|
||||
if res:
|
||||
log = ( res[0], ( "posts", res[1] ) )
|
||||
log_data.append(log)
|
||||
number_scraped = ( res[0], ( "posts", res[1] ) )
|
||||
scraped_summary_list.append(number_scraped)
|
||||
data_methods.print_total(settings["post_ids"], tag, "posts")
|
||||
|
||||
counter += 1
|
||||
@@ -171,14 +130,14 @@ def get_data(hashtags, download_data_type):
|
||||
res = get_videos(settings, tag)
|
||||
if res:
|
||||
res = ( res[0], ( "videos", res[1]))
|
||||
log_data.append(res)
|
||||
scraped_summary_list.append(res)
|
||||
data_methods.print_total(settings["video_ids"], tag, "videos")
|
||||
|
||||
counter += 1
|
||||
if counter < total_hashtags_offset:
|
||||
time.sleep(settings["sleep"])
|
||||
|
||||
return log_data
|
||||
return scraped_summary_list
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
@@ -197,29 +156,15 @@ if __name__ == "__main__":
|
||||
file_name = args.f
|
||||
hashtags = get_hashtag_list(file_name)
|
||||
|
||||
print(hashtags)
|
||||
logger.info(f"Hashtags to scrape: {hashtags}")
|
||||
if not hashtags:
|
||||
logger.exception("No hashtags were given, please use either -t option or -f to provide hashtags.")
|
||||
raise ValueError("No hashtags were specified: please use either the -t flag to specify a sspace-separated list of one or more hashtags as a command-line argument, or use the -f flag to specify a text file of newline-separated hashtags.")
|
||||
|
||||
if (args.p and args.v):
|
||||
download_data_type = {
|
||||
"posts": True,
|
||||
"videos": True
|
||||
}
|
||||
elif args.p:
|
||||
download_data_type = {
|
||||
"posts": True,
|
||||
"videos": False
|
||||
}
|
||||
else:
|
||||
download_data_type = {
|
||||
"posts": False,
|
||||
"videos": True
|
||||
download_data_type = {
|
||||
"posts": args.p,
|
||||
"videos": args.v
|
||||
}
|
||||
|
||||
try:
|
||||
log_data = get_data(hashtags, download_data_type)
|
||||
if log_data:
|
||||
file_methods.log_writer(log_data)
|
||||
except:
|
||||
logger.exception(f"ERROR")
|
||||
scraped_summary_list = get_data(hashtags, download_data_type)
|
||||
if scraped_summary_list:
|
||||
file_methods.log_writer(scraped_summary_list)
|
||||
|
||||
Reference in New Issue
Block a user