diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..f29cd22
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,22 @@
+# Data directory
+data/
+
+# Miscellaneous files
+**/.DS_Store
+*.pyc
+*.ipynb
+*.db
+.env
+*.session
+*.session-journal
+service_account.json
+.vscode/
+*.log
+*.lock
+
+# Unit test / coverage reports
+reports
+.coverage*
+.cache
+.pytest_cache/
+cover/
diff --git a/README.md b/README.md
index f56bc7f..baf9d8a 100644
--- a/README.md
+++ b/README.md
@@ -1,19 +1,21 @@
# TikTok hashtag analysis toolset
-The tool helps to download posts and videos from tiktok for a given set of hashtags. It uses the tiktok-scraper (https://github.com/drawrowfly/tiktok-scraper) to download the posts and videos.
+The tool helps to download posts and videos from TikTok for a given set of hashtags. It uses the [tiktok-scraper](https://github.com/drawrowfly/tiktok-scraper) Node package to download the posts and videos.
## Pre-requisites
-1. Make sure you have python 3.6 or a later version installed.
+1. Make sure you have Python 3.6 or a later version installed.
2. Download and install TikTok scraper: https://github.com/drawrowfly/tiktok-scraper
-3. Go to the project folder and create your virtual environment python3 -m vent env
-4. Start your virtual environment source ./env/bin/activate
-5. Run pip install -r requirements.txt
+3. (Optional) create and activate a virtual environment for this tool, for example by executing the following command, which creates the `env` virtual environment:
+
+ `python3 -m venv env`
+4. Start your virtual environment
+ `source ./env/bin/activate`
+5. Run `pip install -r requirements.txt`
You should now be ready to start using the tool.
-
-### Options for running run_downloader.py
-
+## About the tool
+### Command-line arguments
```
$ python run_downloader.py -h
usage: run_downloader.py [-h] [-t [T [T ...]]] [-f F] [-p] [-v]
@@ -28,10 +30,7 @@ optional arguments:
-v Download videos
```
-
-
-### Data organization
-
+### Structure of output data
```
$ tree ../data
../data
@@ -50,81 +49,106 @@ $ tree ../data
└── data.json
```
-data folder contains all the downloaded data as shown in the picture above.
-1. (Depricated: logging info is now found in logfile.py in the project folder.) the log folder contains log.json which records the total number of downloaded posts and videos for the hashtags against the time stamp of when the script is run.
-2. the ids folder contains two files post_ids.json and video_ids.json that records the ids of the downloaded posts and videos for each hashtag.
-3. Each hashtag has a folder with two subfolders posts and videos that store posts and videos respectively. The posts are stored in the data.json file in the posts folder, and videos are stored as the .mp4 files in the videos folder.
+
+The `data` folder contains all the downloaded data as shown in the tree diagram above.
+- (Depricated: logging info is now found in logfile.py in the project folder.) The `log` folder contains the `log.json` file, which records the total number of downloaded posts and videos for the hashtags against the timestamp of when the script was run.
+- The `ids` folder contains two files `post_ids.json` and `video_ids.json` that record the ids of the downloaded posts and videos for each hashtag.
+- Each hashtag has a folder with two subfolders `posts` and `videos` that store posts and videos respectively. The posts are stored in the `data.json` file in the `posts` folder, and videos are stored as the `.mp4` files in the `videos` folder.
+## How to use
+### Post downloading
+Running the `run_downloader.py` script with the following options will scrape posts containing the hashtags `#london`, `#paris`, or `#newyork`:
-### Post download
-Run the run_downloader.py with the following option:
-```
-$ python3 run_downloader.py -t london paris newyork -p
-['london', 'paris', 'newyork']
-SUCCESS - 962 entries added to ../data/london/posts/data.json!!!
-SUCCESS - 962 entries added to ../data/ids/post_ids.json!!!
-Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/london/posts/london_1651533070680.json!!!
-Total posts for the hashtag london are: 962
-SUCCESS - 961 entries added to ../data/paris/posts/data.json!!!
-SUCCESS - 961 entries added to ../data/ids/post_ids.json!!!
-Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/paris/posts/paris_1651533102789.json!!!
-Total posts for the hashtag paris are: 961
-SUCCESS - 941 entries added to ../data/newyork/posts/data.json!!!
-SUCCESS - 941 entries added to ../data/ids/post_ids.json!!!
-Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/newyork/posts/newyork_1651533125549.json!!!
-Total posts for the hashtag newyork are: 941
-Successfully logged 2864 entries!!!!
-```
+ python3 run_downloader.py -t london paris newyork -p
-1. The --h option allows to type in hashtag list in the commandline.
-2. -p option specifies the download posts option.
+and will produce an output similar to the following log:
+ $ python3 run_downloader.py -t london paris newyork -p
+ ['london', 'paris', 'newyork']
+ SUCCESS - 962 entries added to ../data/london/posts/data.json!!!
+ SUCCESS - 962 entries added to ../data/ids/post_ids.json!!!
+ Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/london/posts/london_1651533070680.json!!!
+ Total posts for the hashtag london are: 962
+ SUCCESS - 961 entries added to ../data/paris/posts/data.json!!!
+ SUCCESS - 961 entries added to ../data/ids/post_ids.json!!!
+ Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/paris/posts/paris_1651533102789.json!!!
+ Total posts for the hashtag paris are: 961
+ SUCCESS - 941 entries added to ../data/newyork/posts/data.json!!!
+ SUCCESS - 941 entries added to ../data/ids/post_ids.json!!!
+ Successfully deleted /Users/work/Documents/development_projects/Tiktok/tiktok/data/newyork/posts/newyork_1651533125549.json!!!
+ Total posts for the hashtag newyork are: 941
+ Successfully logged 2864 entries!!!!
-### Video download
- python3 run_downloader.py --h london -v
+- The `-t` flag allows a space-separated list of hashtags to be specified as a command line argument
+- The `-p` flag specifies that posts, not videos, will be downloaded
-1. --h option allows to type in the list of hashtags as command line argument.
-2. -v option is for downloading the videos
-The above code download all the trending videos for the hashtag london. Note that video downloading is a time and data rate consuming task, as a result we strongly recommend to use one hashtag at a time so as to avoid complications.
+### Video downloading
+Running the `run_downloader.py` script with the following options will scrape trending videos containing the hashtags `#london`, `#paris`, or `#newyork`:
+` python3 run_downloader.py -t london -v`
+- The `-t` flag allows a space-separated list of hashtags to be specified as a command line argument
+- The `-v` flag specifies that videos, not posts, will be downloaded
+Note that video downloading is a time and data rate consuming task, as a result we strongly recommend using one hashtag at a time when using the `-v` flag to avoid complications.
+
+## Analyzing results
### Top n hashtag occurrences
-In the analytics folder, the file hashtag_frequencies.py will plot the frequencies of top occurring hashtags in a given set of posts.
-Assume we want to plot the graph of top 20 occurring hashtags in the downloaded posts of the hashtag london.
-
-1. Plotting the saving the image as a png file: python3 hashtag_frequencies.py -p ../data/london/posts/data.json 20 -v
-
- -
-The figure above shows the top 20 occurring hashtags among all the posts downloaded for the hashtag london. Clearly, the highest occurrence will be of the hashtag london as the file
-
-The figure above shows the top 20 occurring hashtags among all the posts downloaded for the hashtag london. Clearly, the highest occurrence will be of the hashtag london as the file data/london/posts/data.json contain all the posts with hashtag london.
-
-2. Printing the result in the shell: python3 hashtag_frequencies.py -d ../data/london/posts/data.json 20 -v
+The script `hashtag_frequencies.py` analyzes the frequencies of top occurring hashtags in a given set of posts.
```
-Rank Hashtag Occurrences Frequency (Occurrences/Total-Posts(total_posts))
-0 london 962 1.0
-1 fyp 493 0.5124740124740125
-2 uk 238 0.24740124740124741
-3 foryou 223 0.23180873180873182
-4 foryoupage 186 0.19334719334719336
-5 viral 177 0.183991683991684
-6 fypシ 85 0.08835758835758836
-7 funny 55 0.057172557172557176
-8 xyzbca 52 0.05405405405405406
-9 england 45 0.04677754677754678
-10 british 44 0.04573804573804574
-11 trending 39 0.04054054054054054
-12 fy 33 0.034303534303534305
-13 comedy 32 0.033264033264033266
-14 roadman 28 0.029106029106029108
-15 4u 27 0.028066528066528068
-16 usa 26 0.02702702702702703
-17 tiktok 26 0.02702702702702703
-18 travel 21 0.02182952182952183
-19 america 20 0.02079002079002079
-```
+python hashtag_frequencies.py --help
+usage: hashtag_frequencies.py [-h] [-p] [-d] input_file n
-The same result of 1 is printed in the shell. The last column shows the ratio of the occurrence to the total posts.
+positional arguments:
+ input_file The json hashtag file name
+ n The number of top n occurrences
+optional arguments:
+ -h, --help show this help message and exit
+ -p, --plot Plot the occurrences
+ -d, --print List top n hashtags
+ ```
+Assume we want to analyze the top 20 occurring hashtags in the downloaded posts of the `#london` hashtag.
+
+- The results can be plotted and saved as a PNG file by executing the following command:
+
+ `python3 hashtag_frequencies.py -p ../data/london/posts/data.json 20`
+
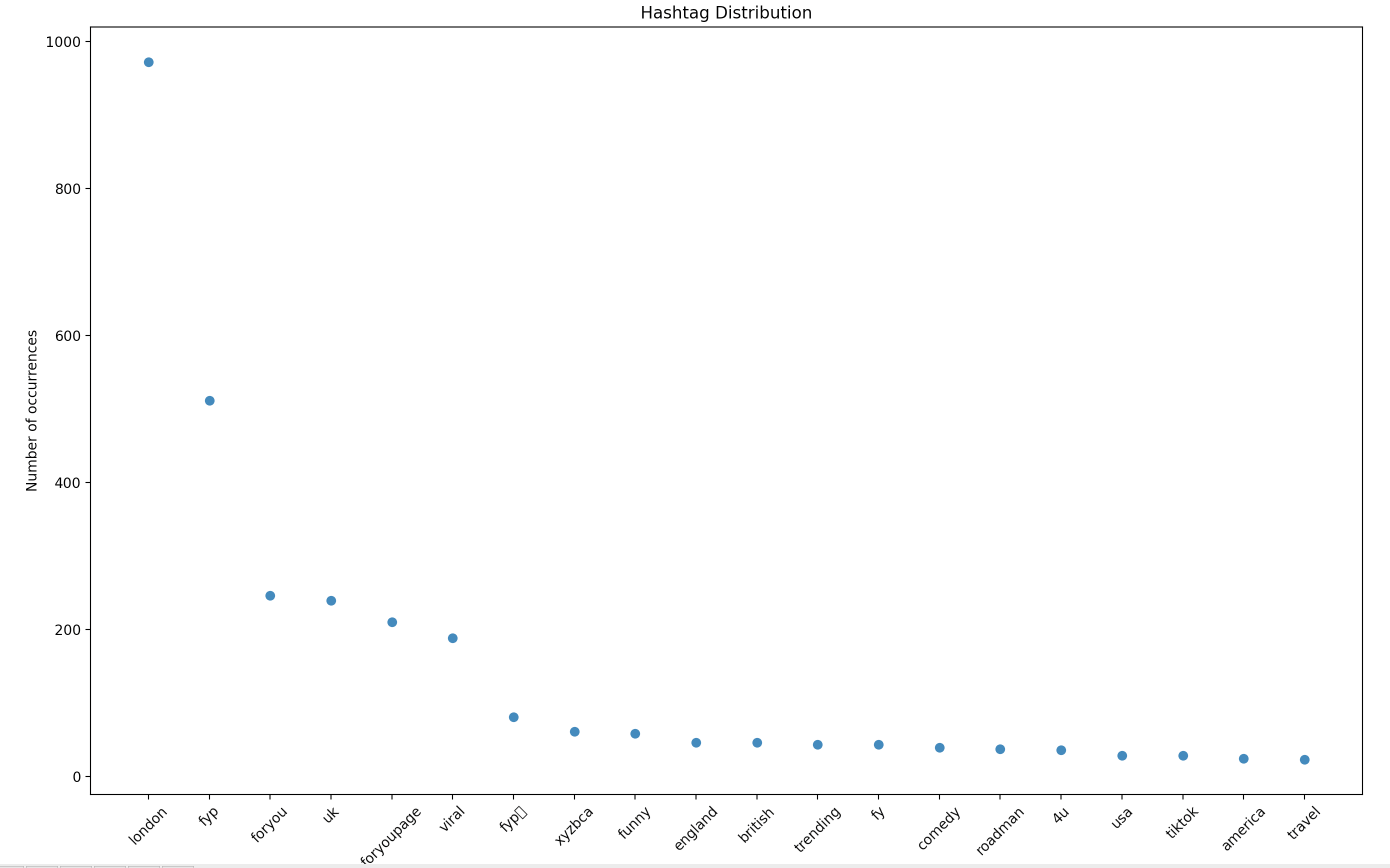
+ which will produce a figure similar to that shown below:
+
+ 
+
+ Clearly, the highest occurrence will be of the `#london` hashtag, as all posts in the file `data/london/posts/data.json` contain the hashtag `#london`.
+
+- The results can be displayed in tabular form by executing the following command:
+
+ `python3 hashtag_frequencies.py -d ../data/london/posts/data.json 20`
+
+ which will produce a terminal output similar to the following:
+ ```
+ Rank Hashtag Occurrences Frequency (Occurrences/Total-Posts(total_posts))
+ 0 london 962 1.0
+ 1 fyp 493 0.5124740124740125
+ 2 uk 238 0.24740124740124741
+ 3 foryou 223 0.23180873180873182
+ 4 foryoupage 186 0.19334719334719336
+ 5 viral 177 0.183991683991684
+ 6 fypシ 85 0.08835758835758836
+ 7 funny 55 0.057172557172557176
+ 8 xyzbca 52 0.05405405405405406
+ 9 england 45 0.04677754677754678
+ 10 british 44 0.04573804573804574
+ 11 trending 39 0.04054054054054054
+ 12 fy 33 0.034303534303534305
+ 13 comedy 32 0.033264033264033266
+ 14 roadman 28 0.029106029106029108
+ 15 4u 27 0.028066528066528068
+ 16 usa 26 0.02702702702702703
+ 17 tiktok 26 0.02702702702702703
+ 18 travel 21 0.02182952182952183
+ 19 america 20 0.02079002079002079
+ ```
+
+ The `Frequency` column shows the ratio of the occurrence to the total number of downloaded posts.
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
index 3f38370..8039c23 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,10 +1 @@
-cycler==0.11.0
-fonttools==4.33.3
-kiwisolver==1.4.2
-matplotlib==3.5.2
-numpy==1.22.3
-packaging==21.3
-Pillow==9.1.0
-pyparsing==3.0.8
-python-dateutil==2.8.2
-six==1.16.0
+matplotlib==3.5.2
\ No newline at end of file
diff --git a/tiktok_downloader/data_methods.py b/tiktok_downloader/data_methods.py
index a6f62e6..6f3bd1d 100644
--- a/tiktok_downloader/data_methods.py
+++ b/tiktok_downloader/data_methods.py
@@ -1,7 +1,4 @@
-import os
from collections import namedtuple
-from datetime import datetime
-import global_data
import file_methods
# setting up the logging
@@ -37,7 +34,7 @@ def get_difference(tag, file, ids):
set_ids = set(ids)
new_ids = set_ids.difference(set_current_ids)
if not new_ids:
- return
+ return None
else:
new_ids = list(new_ids)
total_new_ids = len(new_ids)
@@ -78,7 +75,7 @@ def extract_posts(settings, file_name, tag):
logger.warn(f"WARNING: No new posts were found in the downloaded file - {file_name}")
return
elif new_ids.filter_posts:
- new_posts = [ post for post in posts if post['id'] in new_ids.ids ]
+ new_posts = [post for post in posts if post['id'] in new_ids.ids]
new_data = (new_ids.ids, new_posts)
return new_data
else:
diff --git a/tiktok_downloader/file_methods.py b/tiktok_downloader/file_methods.py
index 5d27c27..04ec236 100644
--- a/tiktok_downloader/file_methods.py
+++ b/tiktok_downloader/file_methods.py
@@ -33,7 +33,7 @@ def create_file(name, file_type):
def check_existence(file_path, file_type):
"""
- Checks the existence of a file or a directory. If not found, returns a False, else returns a true.
+ Checks the existence of a file or a directory. If not found, returns False, else returns True.
"""
if (file_type == "file"):
return os.path.isfile(file_path)
@@ -64,19 +64,15 @@ def download_posts(settings, tag):
os.chdir(path)
try:
tiktok_command = f"tiktok-scraper hashtag {tag} -t 'json'"
- result = subprocess.run([tiktok_command], capture_output=True, shell=True)
- if result.stdout:
- new_file = result.stdout.decode('utf-8').split()[-1]
- if ("json" in new_file):
- os.chdir("../../../tiktok_downloader")
- return new_file
- else:
- logger.warn(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
- os.chdir("../../../tiktok_downloader")
- return
- else:
+ result = subprocess.check_output(tiktok_command, shell=True)
+ print(result)
+ new_file = result.decode('utf-8').split()[-1]
+ if ("json" in new_file):
+ os.chdir("../../../tiktok_downloader")
+ return new_file
+ else:
+ logger.warn(f"WARNING: Something's wrong with what is returned by tiktok-scraper for the hashtag {tag} - *{new_file}* is not a json file!!!!")
os.chdir("../../../tiktok_downloader")
- logger.warn(f"WARNING: No file was downloaded by the tiktok-scraper for the {tag} !!!!")
return
except: raise
@@ -93,26 +89,21 @@ def download_videos(settings, tag):
try:
# tiktok_command = f"tiktok-scraper hashtag {tag} -n {settings['number_of_videos']} -d"
tiktok_command = f"tiktok-scraper hashtag {tag} -d"
- result = subprocess.run([tiktok_command], capture_output=True, shell=True)
- if result.stdout:
- downloaded_list_tmp = os.listdir(f"./#{tag}")
- if downloaded_list_tmp:
- downloaded_list = []
- for file in downloaded_list_tmp:
- file = file.split('.')[0]
- downloaded_list.append(file)
-
- os.chdir("../../../tiktok_downloader")
- return downloaded_list
- else:
- logger.warn(f"WARNING: No video files were downloaded for the hashtag {tag}.")
- os.chdir("../../../tiktok_downloader")
- shutil.rmtree(settings['videos_delete'])
- #subprocess.call(f"rm -rf {settings['videos_delete']}", shell=True)
- else:
+ result = subprocess.check_output(tiktok_command, shell=True)
+ downloaded_list_tmp = os.listdir(f"./#{tag}")
+ if downloaded_list_tmp:
+ downloaded_list = []
+ for file in downloaded_list_tmp:
+ file = file.split('.')[0]
+ downloaded_list.append(file)
+
os.chdir("../../../tiktok_downloader")
- logger.warn(f"WARNING: Something went wrong with the tiktok-scraper video download for the {tag} !!!!")
- return
+ return downloaded_list
+ else:
+ print(f"WARNING: No video files were downloaded for the hashtag {tag}.")
+ os.chdir("../../../tiktok_downloader")
+ shutil.rmtree(settings['videos_delete'])
+ #subprocess.call(f"rm -rf {settings['videos_delete']}", shell=True)
except: raise
@@ -121,7 +112,7 @@ def get_data(file_path):
"""
Reads the json file and retuns the read data.
"""
- with open(file_path, "r") as f:
+ with open(file_path, "r", encoding = "utf-8") as f:
data = json.load(f)
return data
@@ -130,7 +121,7 @@ def dump_data(file_path, data):
"""
Writes the data to the json file.
"""
- with open(file_path, "w") as f:
+ with open(file_path, "w", encoding = "utf-8") as f:
json.dump(data, f)
return
diff --git a/tiktok_downloader/hashtag_frequencies.py b/tiktok_downloader/hashtag_frequencies.py
index 3f9a07f..9e9e1f9 100644
--- a/tiktok_downloader/hashtag_frequencies.py
+++ b/tiktok_downloader/hashtag_frequencies.py
@@ -1,5 +1,5 @@
import os, sys
-import csv, json
+import json
import argparse
import matplotlib.pyplot as plt
from datetime import datetime
@@ -95,7 +95,7 @@ if __name__ == "__main__":
"-d" option prints the hashtag frequencies on the shell
"-p" option plots the hashtag frequencies and saves as a png file in the folder /data/imgs/
- The function get_occurances is triggered to compute and return the top n occurances and the hashtags.
+ The function get_occurrences is triggered to compute and return the top n occurrences and the hashtags.
"""
img_folder = IMAGES
check_file(img_folder, "dir")
@@ -112,11 +112,10 @@ if __name__ == "__main__":
base = os.path.splitext(args.input_file)[0]
path = f"./{base}_sorted_hashtags.csv"
+ occs = get_occurrences(args.input_file, args.n)
if args.plot:
- occs = get_occurrences(args.input_file, args.n)
plot(args.n, occs, img_folder)
else:
- occs = get_occurrences(args.input_file, args.n)
print_occurrences(occs)
else:
print(f'ERROR: either {args.input_file} or {args.n} or both contains error.')
diff --git a/tiktok_downloader/run_downloader.py b/tiktok_downloader/run_downloader.py
index 39b00ce..0d0c68d 100644
--- a/tiktok_downloader/run_downloader.py
+++ b/tiktok_downloader/run_downloader.py
@@ -1,6 +1,5 @@
-import os, sys
+import os
import time
-import json
import argparse
import global_data
@@ -15,8 +14,6 @@ fileConfig('../logging.ini')
logger = logging.getLogger()
-
-
"""
The run_downloader.py dowloads data using the tiktok-scraper (https://github.com/drawrowfly/tiktok-scraper).
1. "-p" option is used by the user to download posts only
@@ -26,7 +23,7 @@ The run_downloader.py dowloads data using the tiktok-scraper (https://github.com
5. "-f" option is used to read the list of hashtags from the user specified file
Example:
- 1. The command "python3 run_downloader.py --h london paris newyork -p" will download posts for hashtags london, paris and newyork.
+ 1. The command "python3 run_downloader.py -t london paris newyork -p" will download posts for hashtags london, paris and newyork.
2. The command "python3 run_downloader.py -f hashtag_list -p -v" will download posts and videos for hashtags in the file hashtag_list.
@@ -55,8 +52,7 @@ hashtag_list - this file contains the list of hashtags that the user wants to do
def get_hashtag_list(file_name):
try:
with open(file_name) as f:
- gn = (line.strip() for line in f if not line.startswith("#"))
- tags = list(line for line in gn if line)
+ tags = list(filter(None, [line.strip() for line in f if not line.startswith("#")]))
return tags
except IOError:
logger.exception(f"IOError")
@@ -91,7 +87,7 @@ def set_download_settings(download_data_type):
settings["post_ids"] = global_data.FILES["post_ids"]
settings["data_file"] = global_data.FILES["data_file"]
- if download_data_type == "videos":
+ if download_data_type["videos"]:
settings["videos"] = global_data.FILES["videos"]
settings["video_ids"] = global_data.FILES["video_ids"]
@@ -165,7 +161,7 @@ def get_data(hashtags, download_data_type):
if counter < total_hashtags_offset:
time.sleep(settings["sleep"])
- if download_data_type == "videos":
+ if download_data_type["videos"]:
settings = set_download_settings(download_data_type)
while counter < total_hashtags:
tag = hashtags[counter]
@@ -185,24 +181,12 @@ def get_data(hashtags, download_data_type):
return log_data
-
-def get_hashtags(file_name, hashtag_list):
- """
- Loads and returns the list of hashtags from user specified file.
- """
- try:
- from hashtag_list import hashtag_list
- return hashtag_list
- except ImportError:
- logger.exception(f"ERROR: something went wrong while reading the file {file_name}!")
-
-
if __name__ == "__main__":
parser = create_parser()
args = parser.parse_args()
if not (args.t or args.f):
- parser.error("No hashtags were given, please use either --h option or -f to provide hashtags.")
+ parser.error("No hashtags were given, please use either -t option or -f to provide hashtags.")
if not (args.p or args.v):
parser.error("No argument given, please specify either -p for posts or -v videos or both.")
@@ -215,7 +199,7 @@ if __name__ == "__main__":
print(hashtags)
if not hashtags:
- logger.exception(f"No hashtags were given, please use either --h option or -f to provide hashtags.")
+ logger.exception("No hashtags were given, please use either -t option or -f to provide hashtags.")
if (args.p and args.v):
download_data_type = {